



















The Cloud Database Migration Guide for Data Practitioners

Introduction
This is the guide I wish I had 11 years ago when I was doing my first large database cloud migration at the company I was working at. In retrospect, many of the errors that were made could have been avoided, but as they say – hindsight is always 20/20.
Since then, I’ve personally been involved in dozens of small and large scale cloud database migrations, both as an in-house practitioner, and as a solutions engineer working at various data companies.
My hope is that this guide will help you avoid some of the pitfalls and headaches I had to go through at the time.
Table of contents

Each cloud database migration is unique
Sure there are some good rules of thumb and gotchas to be aware of (as I mention below), but every company has its own unique data and infrastructure. Every company has its own priorities, risk tolerance, budgets, resources and timelines. A great migration plan for company A could be overkill or insufficient for company B.
Guides and articles like this one are a great starting point, but please make sure you consult with people who understand your specific needs before actually pulling the trigger.
With that said …. Let’s get started.
What is a cloud database migration – what does it actually mean?
Simply put, cloud database migration means the ability to take a legacy database or warehouse, which is currently stored on-premise / or self-managed, and move its contents and usage to the cloud, either to a relational database (RDBMS) or more commonly to a data warehouse (using columnar storage).
For example, a company might be moving from a MySQL or PostgreSQL on premise database to Snowflake, Redshift or BigQuery, which are the three most common cloud data warehouses.
Why are companies migrating their databases to the cloud?
The main reasons companies are migrating their data to the cloud are scalability, efficiency, costs, and not having to manage your own infrastructure.
We’ll get into the details in a moment, but in a nutshell, for most organizations, managing and hosting your own database is simply not worth the headache. You’re gonna need a DBA (database administrator) to manage and maintain the database server, worry about patches and software updates, deal with scalability and backups, etc.
Here are some specific advantages you’ll gain from moving your database to the cloud.
Scalability
Both in terms of performance and data size, with cloud vendors, you can easily ramp up the size of your data and/or increase performance with zero downtime. Some solutions, such as Snowflake and Firebolt even separate compute power from storage. This means you can provide one group of users with less powerful (but much cheaper) compute engines to perform analysis, while providing another use case, like a daily report process, with more powerful (albeit more expensive) data engines.
This also addresses the issue of peak usage patterns. For example, a company that needs to run monthly reports on the first of every month will often need an extra boost of computing power to run the reports, but does not need all that horsepower during most of the month.
Cost Savings
As mentioned before, with cloud databases, you don’t need any internal DBA to manage or maintain your database servers and an internal IT professional to maintain infrastructure. You also don’t need to pay for any software licensing fees or hardware, so you have zero upfront or fixed costs.
With most cloud solutions, pricing is usage based, so the more you use it, or the more compute power you’re using, the more you’re paying. While storage costs are also a factor with cloud databases, from what we’ve seen, storage costs are usually smaller than compute costs.
For example, Snowflake storage costs are about $24 a month per terabyte of stored data, so for 50TB of data storage, you’d be paying less than $15k a year.
Please note – two things to keep in mind:
- For some use cases, moving to the cloud could potentially cost more in the long run. For example, if your monthly costs are higher than the fixed costs of having two dedicated DBAs on staff + software + hardware costs.
- If you’re not careful, it can be easy to rack up costs with usage based pricing. Be sure to keep an eye on this.
Separating your operational and reporting / analytical database solutions.
It’s not uncommon for companies to use the same database solution for operational needs and for reporting/analytics needs, especially smaller organizations. As data sizes and connectivity needs increase, it usually makes sense to separate these two needs into two distinct systems.
One common differentiator between a system being used for operations vs reporting is storing data in rows vs columns.
“Legacy” databases, such as Oracle or MS SQL server, have been around for decades and were initially created to be relational in nature. This means they are built and optimized for operations and transactions – frequent inserts, updates and deletes. For example the back end of an ecommerce store, SaaS application, or bank.
While databases shine in transactional performance, they were not built for reporting, and do not scale or perform well for analytics purposes. Whereas data warehouses are usually columnar, and were built and optimized to perform well at scale when used for analytics purposes. On the flip side, most data warehouses do not perform well if you’re trying to constantly insert new data, or update / delete existing data.
You’ll often hear the terms operational database and analytical database to describe the two main use cases they are being used for – back end operations and reporting.
Reliability
When you’re in the business of providing a cloud database or data warehouse, excuse my French, but you better damn be reliable 100% of the time – anything less doesn’t cut it. That’s why cloud vendors have a lot of redundancies and backups in place. Without going into details (since to be honest, I don’t know the details myself) I’d make a bet that any of the top cloud vendors provide a solution that is more resilient than what you’re hosting in-house, unless you happen to be NASA or the likes 🙂
Reduced risk of lost data
Availability aside (just having the system online) a hardware failure or natural disaster can be catastrophic in terms of lost data. Most cloud solutions provide various levels of backups, redundancies and even geographically distributed servers, assuring a random strike of lightning won’t wipe out your data.
Improved Security
There, I said it. I’ve read a lot of articles online that actually say that moving to a cloud database reduces your security. Maybe that was true a few years ago, but I’d say that’s no longer the case, and is only a perceived issue, not a real one.
While with an on-premise database, you physically are in control of the hardware, cloud database providers have dedicated security teams and monitoring systems working 24/7 to keep unauthorized users out of your data.
Database Migration Strategies
Here are three different strategies I’ve seen mentioned:
Big Bang database migration
This is a hard cut off from the old system to the new one, done at a single point in time (like over the weekend). Personally, this sounds like an out-of-date idea and very scary to me. With this method, it can be difficult to make sure the new and old systems are in sync, and if when something goes wrong, rolling back the migration is a nightmare.
Piecemeal database migration (also called trickle migration)
The idea here is to break down the overall migration into smaller individual projects that can be migrated individually of each other. This is a good idea in terms of being able to start slow and small, spreading the migration over time, though it introduces an added layer of complexity. Some systems will be using the old database and some systems using the new database, which might be a deal breaker in terms of having all of the data you need in one place.
Parallel live migration (also called zero-downtime migration or live-live migration)
The goal of this migration strategy is to have both the old and new databases “live” in parallel with production data.
This strategy is definitely my preference. Here’s why. There is going to be a point where either something goes wrong, or some data is missing, or the data in the new system doesn’t match the data in the old system.
Any way you look at it, you’re going to need two things that only parallel live migration provides:
- Ongoing validation that the data in the old and new systems match
- An easy way to test the new system with live data and live reports
- Be able to reliably roll back if needed.
With that in mind, let’s take a deep dive into a breakdown of the process.
Cloud Database Migration Process
The 5 stages of a parallel live migration
- Migrating historical data from the old to the new system
- Keeping the two systems in sync
- Validating the data in the new system
- Switching the new system to production
- Sunsetting the old system
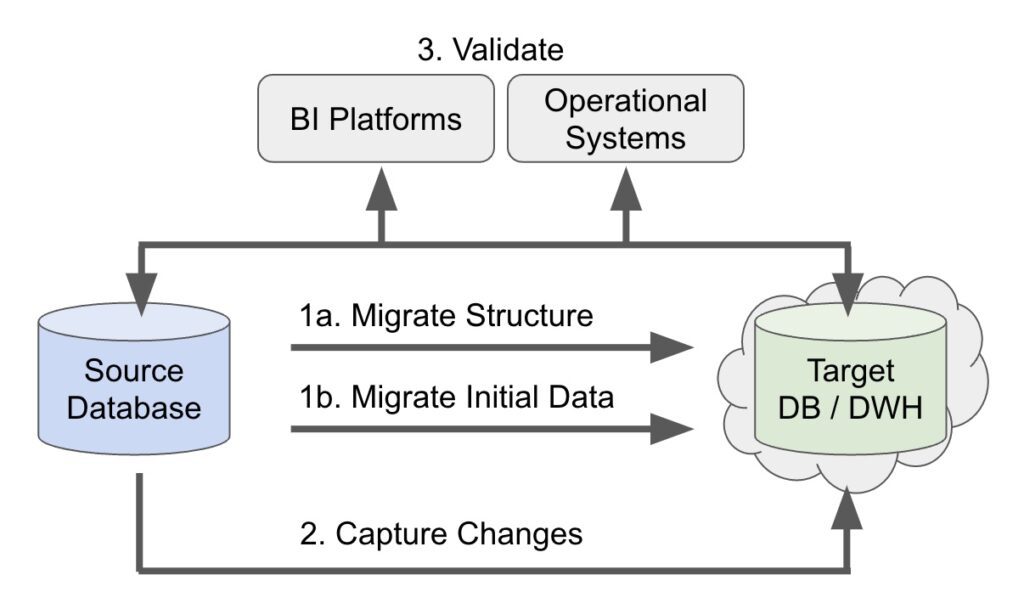
1. Migrate data from the old to the new system
In some ways this is the easiest and in other ways, sometimes the hardest of the stages
Before you migrate any of the data, you’ll need to figure out how to deal with differences between the two systems. While most databases and data warehouses support the same basic SQL commands at their core, every SQL based solution has its own specific “special sauce” and features that go beyond ANSI SQL standards.
For example, how databases deal with JSON data, or arrays of data in a single cell. What they support in terms of data types, indexes, stored procedures, views, triggers, foreign keys, and functions are just a few of the common differences between databases.
You’ll also want to take advantage of new features or functionality provided by the cloud database. For instance, if you’re moving from a relational to a columnar database it’s time to rethink your data structure. Also, if you’re replicating your existing structure may also replicate existing issues / blockers into the new data warehouse.
The actual migration of historic data up to a specific date in the recent past, is usually not the hard part. From my experience, it’s better to use a specific end date, like the end of last month for the initial data dump and load. This is because it is rarely 100% perfect on the first load. If you’re doing a data dump with an end date of “today” it will be much harder to do a diff between data loads done on different days.
If you’re migrating a lot of data, here are two other tips for the initial migration.
- Start with a relatively small, but well defined subset of data, let’s say orders from Jan 1st to Jan 31st of 2022, or users with IDs 0 to 1,000,000. Start doing your data validation on that subset of data and only after you’ve validated everything, move on to the rest of the data.
- Depending on data size (are we talking big data or XXXL data?) migrate it in chunks. I can’t remember how many times my imports failed mid-stream, which is very annoying if it takes a few hours per import. You also need to be considering any potential bottlenecks or systems choking on large files.
2. Keep the two systems in sync
Danger Will Robinson – Do not try to build your own solution to do this 🙂
The whole point of moving to the cloud is so you don’t have to deal with managing the infrastructure yourself. There are plenty of excellent tools and SaaS platforms available which deal with this very problem, so don’t reinvent the wheel. Which tool is best for your specific needs is beyond the scope of this guide
One of the biggest decisions to make is how often you’ll need to sync data to the new cloud solution. Do you need 5 minute syncs? Or is it enough to sync once every 15 minutes, every hour or maybe just once a day? Make sure to ask your stakeholder what they really need, vs just what would be nice to have.
You can always go back and change your mind, for example going from once a day to once every 15 minutes – just be sure you’re aware of possible implications such as added costs or API limits, etc.
Also make sure the solution you choose can deal gracefully with outages and failures. If for some reason a sync fails, or a source system is offline, make sure your solution can pick up from where it left off, ideally for up to 48 hours so it can handle those “being offline all weekend and you just realized it Monday morning” situations.
Many tools (like Rivery) can take care of the both initial historic data load (step 1 above), and keeping the two systems in sync – providing a single solution for your data migration needs.
In terms of sync mechanics, there are two fundamentally different approaches to reading data from the source database:
- Connecting to the database and getting data using Select statements
- Reading from a log file that captures changes in the database
The latter methodology has many advantages and is called Change Data Capture, or CDC for short.
CDC is a methodology of capturing data changes in a source database in order to pass these updates to a target database or data warehouse in near real time. Most CDC solutions incorporate some type of logging system for the source database, and then read the data from the logs in order to make the changes to the target system. Example types of changes that are being tracked are inserts, updates, deletes, and schema changes.
To learn more about CDC and understand the pros and cons, check out What is Change Data Capture.
3. Validate the data in the new system
Now you need to start comparing the data in system A (your on-prem database) with the data in system B (your cloud solution). My suggestion is to start with high level aggregated data, usually in the form of reports, and then drill down into smaller chunks of data, or even line items as needed.
For example, let’s say I am dealing with ecommerce data. I would start with comparing top level metrics for the entire year of 2021. Total sales in dollars, total number of orders, etc. You probably already have a reporting solution that provides you with all of this information (please don’t tell me that you don’t 😱), so ideally you’re comparing two sets of reports – one that is using the data from the old system and one that is using the data from the new system.
If there are any discrepancies, looking at more granular data and different metrics will help you find what’s causing the issue. For example, are there the same number of orders? Same number of customers, etc. Once everything looks good at the top level, you’ll still want to validate and compare the data at a more granular level in any case, as averages to totals can hide discrepancies that cancel each other out (yes, I’ve seen this as well).
Depending on your needs, trying to compare the two systems manually by simply looking at reports won’t be enough, so you’ll want to create new reports and queries that compare the data from the two systems.
For example, don’t just show me daily sales for both systems, show me the delta in daily sales between system A and system B.
Aside from looking at the data values, it’s also important to run some metadata checks (i.e. check that all tables/columns were created in the destination database as well) and run some reports at the SQL level as well. Here are some examples:
General Validation Tests
Table Comparison
Goal: Validate the same table names in each schema related to the chosen Data Sources.
Compare type: Metadata.
Query example (MySQL): select TABLE_NAME from INFORMATION_SCHEMA.TABLES where TABLE_SCHEMA = 'XXX'
Total Rows
Goal: Validate the same number of rows in each table related to the chosen Data Sources.
Compare type: Raw Data.
Query example (MySQL): select TABLE_NAME, table_rows as TOTAL_ROWS from INFORMATION_SCHEMA.TABLES where TABLE_SCHEMA = 'XXX'
Specific Validation Tests
Sum Checks
Goal: Comparison of all the columns of Numeric data type.
Compare type: Aggregated Data
String Checks
Goal: Compare String length values for all the columns of String data type.
Compare type: Aggregated Data.
Table Structure
Goal: Compare column structure for each column in the table.
Compare type: Metadata.
How long should the two systems be running in parallel?
The short answer is – it depends.
The longer answer is anywhere between two to thirteen months (yes, over a year).
Let’s start with thirteen months.
On one end of the spectrum, you have instances where risk tolerance is zero, and the cost of running two databases in parallel is much lower than the downside of having bad data in the new system.
When I was doing cloud database migrations for banks, this was the case. Thirteen months was the time frame chosen to ensure that year end reports, and anything else that was happening during the year was tested.
On the other end of the spectrum, if the downside of bad data is “woops”, then two months should be enough to test and spot inconsistencies between the two systems.
Another step to take during the validation stage is to measure performance and costs. Having at least two months of both systems running in parallel should provide a good estimate of how performance and monthly costs compare between the two systems, and give you ample time to optimize both if needed.
4. Switch the new system to production
Once you’ve verified and validated the data in the new database looks good, and that performance and costs are in-line with what you expected, it’s time to “flip the switch”.
How this is done depends heavily on the specifics of your individual use case, but the two important things are:
- The switch can be done with zero downtime.
- It’s fairly easy to revert back if needed.
After switching to the new system, it’s very important to run yet another round of validation and performance testing, especially if you now have more people using systems that are connected to the new database.
Now is also the time to validate that the old system is still being updated and staying in sync with the new system in case you need to revert.
5. Sunset the old system
Congratulations! If you’ve reached this far, you’re in a good place 🙂
While turning off the old database itself should be a fairly simple procedure, now is the time to make sure you’re not connected to it anywhere in your infrastructure. A good place to check for this is in your errors logs and monitoring systems.
Once the old system has been shut down, make sure to notify everyone internally, and then pour yourself a drink.
What are common mistakes to avoid for cloud database migration?
Lack of system specific experience
People assume that because they have a MS SQL Server DBA who knows all of the ins and outs of SQL Server, then they’ll automatically be able to transfer those skills and knowledge to a cloud data warehouse like Snowflake.
This has a knock on effect to performance, cost, et cetera, as well. They’re totally two different worlds. It’s like saying that because I know how to drive a car, I can handle a motorcycle or a F1 race car. Yes, they are both vehicles, but they’re totally different in terms of their constituent elements.
Therefore you’ve got to make sure that your DBA or consulting partner fully understands how to optimize the new data warehouse and take advantage of all of its features – this is often called database refactoring.
Refactoring involves completely rebuilding a resource to make more effective use of a cloud-native environment. Here are examples of refactoring different types of data:
Structured data — when migrating to the cloud, many organizations change their data format from traditional SQL tables to NoSQL key-value pairs. This lets them leverage massively scalable, high-performance databases.
Unstructured data — cloud providers offer value-added services that can be used to prepare, process, and extract insight from unstructured data. By applying these services while ingesting the data, organizations can derive additional value from existing assets. For example, instead of just copying video assets to the cloud, an organization can use AI services or video APIs to extract tags, concepts, transcripts, and other data from video content.
Sensitive data — sensitive data can be restructured to make it easier to manage and secure in the cloud. For example, a large table containing both sensitive and non-sensitive data can be broken up into separate tables, or even completely separate databases, to enable stronger control over access and authorization.
Please note: Depending on the complexity of the changes you want to make, it may be easier to lift and shift as is, and then work on refactoring at a later stage.
Not having a dedicated project manager
You can’t have the DBA entirely in charge of the migration project, you should have a dedicated project manager to manage the project and everyone involved. The technical aspect of cloud database migration is just one part of the puzzle and you need someone to be on top of communication, documentation, risk management, QA, adherence to timelines, etc.
Doing it on your own
Depending on the scope and risk tolerance of your migration project, this might not be a mistake per-se, but keep in mind that the first time you do something is when you’ll make the most mistakes. Hiring an outside consulting firm or consultant to manage the project and provide guidance is usually a good idea, and if nothing else, get a good second opinion on your existing plan.
Not using the right tool(s) for the job
If all you know how to use is a hammer, everything looks like a nail. Do a Google search for Cloud Database Migration tools and you’ll get a plethora of results. The truth is that there’s more than one tool suitable for your specific needs (like Rivery of course), just make sure you don’t choose a solution based purely on the tools your internal team are familiar with.
Not setting up clear communications, expectations and responsibilities in advance.
Cloud database migrations are complex projects with many moving parts and people involved. Scope creep and missed deadlines are all too common.
Make sure to have a clear plan of what the project entails, which is distributed to all relevant people, and have a good channel of communication. For example, an internal slack channel for Q&A and project updates.
Summary
I hope you learned something new in this guide about cloud database migration. As I mentioned earlier, every migration project is unique, so be sure to ask your friends and colleagues and consult with people who have done this before. It’s dangerous to go alone. 🗡️
Speaking of which, working at Rivery means that every day I help organizations on their cloud database migration journey. Our solutions engineering team has helped over a hundred companies make the jump to a cloud database. We’ve worked with both small startups and fortune 500 companies, so chances are we can help you as well.
If you’re just starting your cloud database migration, or even in the middle of it and want some help, no-strings-attached, please get in touch.



Minimize the firefighting. Maximize ROI on pipelines.

