



















What is the Difference Between ETL and ELT?

What is the difference between ETL and ELT?
ETL and ELT are two common approaches in data integration.
ETL, which stands for Extract, Transform, and Load, involves transforming data on a separate processing server before transferring it to the data warehouse.
On the other hand, ELT, or Extract, Load, and Transform, performs data transformations directly within the data warehouse itself. Unlike ETL, ELT allows for raw data to be sent directly to the data warehouse, eliminating the need for staging processes.
ETL and ELT are data integration methods. Their main task is to transfer data from one place to another. However, each has unique characteristics and is suitable for different data needs. Their most important difference is that ETL transforms data before loading it on the server, while ELT transforms it afterward.
ETL is an older method ideal for complex transformations of smaller data sets. It’s also great for those prioritizing data security. On the other hand, ELT is a newer technology that provides more flexibility to analysts and is perfect for processing both structured and unstructured data.
Your decision between ETL and ELT will determine your data storage, analysis, and processing. So, before choosing between the two methods, it’s important to consider all factors. This includes the type of business you are running and your data needs.
Read on to discover everything you need to choose the right data integration method for your business.
What is ETL (Extract, Transform, Load)?
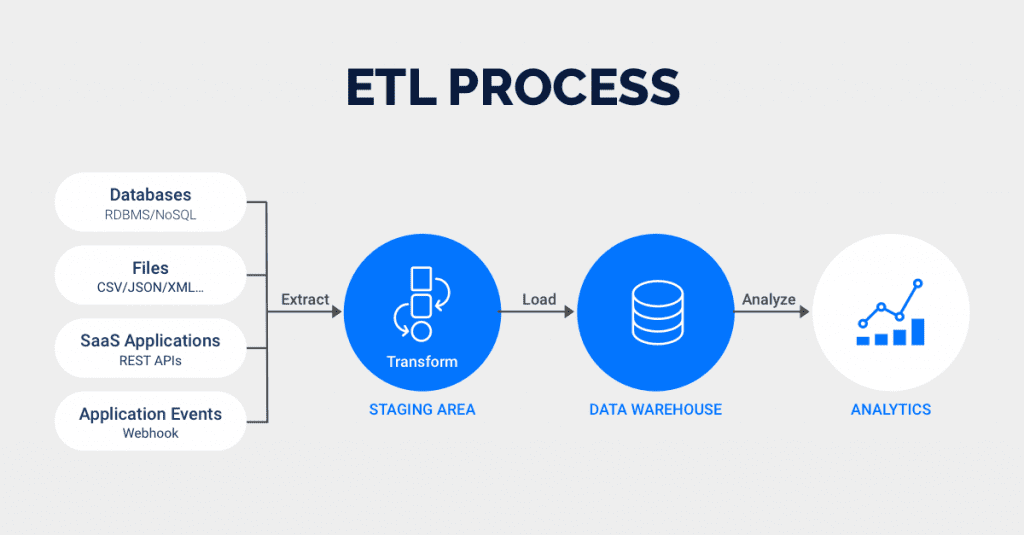
Extract, transform, and load (ETL) is a data integration methodology that extracts raw data from sources, transforms the data on a secondary processing server, and then loads the data into a target database.
ETL is used when data must be transformed to conform to the data regime of a target database. The method emerged in the 1970s, and remains prevalent amongst on-premise databases that possess finite memory and processing power.
Consider an example of ETL in action. Online Analytical Processing (OLAP) data warehouses only accept relational SQL-based data structures.
With this kind of data warehouse, a protocol such as ETL ensures compliance by routing the extracted data to a processing server, and then transforming the non-conforming data into SQL-based data.
The extracted data only moves from the processing server to the data warehouse once it has been successfully transformed.
What Is ELT (Extract, Load, Transform)?

Unlike ETL, extract, load, and transform (ELT) does not require data transformations to take place before the loading process.
ELT loads raw data directly into a target data warehouse, instead of moving it to a processing server for transformation.
With ELT data pipeline, data cleansing, enrichment, and data transformation all occur inside the data warehouse itself. Raw data is stored indefinitely in the data warehouse, allowing for multiple transformations.
ELT is a relatively new development, made possible by the invention of scalable cloud-based data warehouses.
Cloud data warehouses such as Snowflake, Amazon Redshift, Google BigQuery, and Microsoft Azure all have the digital infrastructure, in terms of storage and processing power, to facilitate raw data repositories and in-app transformations.
Although ELT data pipeline is not used universally, the method is becoming more popular as companies adopt cloud infrastructure.
ETL vs ELT: How is ETL Different from the ELT Process?
ETL and ELT differ in two primary ways. One difference is where the data is transformed, and the other difference is how data warehouses retain data.
- ETL transforms data on a separate processing server, while ELT transforms data within the data warehouse itself.
- ETL does not transfer raw data into the data warehouse, while ELT sends raw data directly to the data warehouse.
For ETL, the process of data ingestion is made slower by transforming data on a separate server before the loading process.
ELT, in contrast, delivers faster data ingestion, because data is not sent to a secondary server for restructuring. In fact, with ELT, data can be loaded and transformed simultaneously.
The raw data retention of ELT creates a rich historical archive for generating business intelligence. As goals and strategies change, BI teams can re-query raw data to develop new transformations using comprehensive datasets. ETL, on the other hand, does not generate complete raw data sets that are endlessly queryable.
These factors make ELT more flexible, efficient, and scalable, especially for ingesting large amounts of data, processing data sets that contain both structured and unstructured data, and developing diverse business intelligence.
How you process unstructured data is crucial. At the moment, ELT is the best option for it. It provides superior processing of semi-structured and unstructured data compared to ETL, which is typically used for structured data.
The majority of data is unstructured (images, videos, PDF files, PowerPoint documents, etc.), yet this type of data is still harder to access and process. In the future, the industry will focus on eliminating difficulties and improving the interpretation of this unstructured data, and ELT will play a significant role in that.
On the other hand, ETL is ideal for compute-intensive transformations, systems with legacy architectures, or data workflows that require manipulation before entering a target system, such as erasing personal identifying information (PII).
The data pipeline of both ETL and ELT includes cleaning and filtering. It is a key part of the data transformation process. And because the ETL method completes transformation before loading data into the server, it is better for meeting compliance standards and transferring sensitive data.
Most companies are required to encrypt, remove, or mask data to protect their client’s privacy. If they do not try their best to do so, they may violate compliance standards and risk the client’s sensitive data.
Sometimes this happens unintentionally. But with ETL, you will reduce the risk of transferring non-compliant data. Why? Because of the data pipeline, meaning the data is cleaned and filtered before it leaves its initial destination.
ETL vs ELT: Side-by-Side Comparison
Category | ETL | ELT |
Definition | Data is extracted from a source system, transformed on a secondary processing server, and loaded into a destination system. | Data is extracted from a source system, loaded into a destination system, and transformed inside the destination system. |
Extract | Raw data is extracted using API connectors. | Raw data is extracted using API connectors. |
Transform | Raw data is transformed on a processing server. | Raw data is transformed inside the target system. |
Load | Transformed data is loaded into a destination system. | Raw data is loaded directly into the target system. |
Speed | ETL is a time-intensive process; data is transformed before loading into a destination system. | ELT is faster by comparison; data is loaded directly into a destination system, and transformed in-parallel. |
Code-Based Transformations | Performed on secondary server. Best for compute-intensive transformations & pre-cleansing. | Transformations performed in-database; simultaneous load & transform; speed & efficiency. |
Maturity | Modern ETL has existed for 20+ years; its practices & protocols are well-known and documented. | ELT is a newer form of data integration; less documentation & experience. |
Privacy | Pre-load transformation can eliminate PII (helps for HIPPA). | Direct loading of data requires more privacy safeguards. |
Maintenance | Secondary processing server adds to the maintenance burden. | With fewer systems, the maintenance burden is reduced. |
Costs | Separate servers can create cost issues. | Simplified data stack costs less. |
Requeries | Data is transformed before entering destination system; therefore raw data cannot be requeried. | Raw data is loaded directly into destination system and can be requeried endlessly. |
Data Lake Compatibility | No, ETL does not have data lake compatibility. | Yes, ELT does have data lake compatibility. |
Data Output | Structured (typically). | Structured, semi-structured, unstructured. |
Data Volume | Ideal for small data sets with complicated transformation requirements. | Ideal for large datasets that require speed & efficiency. |
A Brief History: ETL & ELT Processes
Today, businesses across the spectrum require data integration to centralize, access, and activate data across their organizations. Businesses must leverage dozens or hundreds of different data sources, across countries, continents, and teams, to drive results in the data-driven economy. In this complex, fractured landscape, combining multiple data sources into a unified view has never been more important. But this challenge is nothing new. Data integration has vexed organizations since the dawn of the digital era.
The first inventions of the modern computer age laid the groundwork for the unique function of data integration. In the late 1960s, disk storage supplanted punch cards, enabling direct access to data. Not long after, IBM and other companies pioneered the first Database Management Systems (DBMS). These advancements soon led to the sharing of data between computers. Almost immediately, the cumbersome process of integrating data and data sources with external machines became a challenge.
ETL, the first standardized method for facilitating data integration, emerged in the 1970s. ETL rose to prominence as enterprise businesses adopted multi-pronged computer systems and heterogeneous data sources. These businesses needed a way to aggregate and centralize data from transactions, payroll systems, inventory logs, and other enterprise resource planning (ERP) data.
With the rise of data warehouses in the 1980s, ETL became even more essential. Data warehouses could integrate data from a variety of sources, but typically required custom ETLs for each data source. This led to an explosion of ETL tools. By the end of the 1990s, many of these solutions finally became affordable and scalable for mid-market businesses, not just large enterprises.
With the emergence of cloud computing in the 2000s, cloud data lakes and data warehouses caused a new evolution: ELT. With ELT, businesses could load unlimited raw data straight into a cloud DWH. Engineers and analysts could execute an infinite number of SQL queries on top of this raw data, directly inside the cloud data warehouse itself. For the first time, businesses could unlock the analytical firepower and efficiency that big data had always promised. Combined with visualization tools and cloud DWHs, ELTs ushered in a new era of analytics and data-driven decision-making.
Simple Solutions for Complex Data Pipelines
Rivery's SaaS ELT platform provides a unified solution for data pipelines, workflow orchestration, and data operations. Some of Rivery's features and capabilities:- Completely Automated SaaS Platform: Get setup and start connecting data in the Rivery platform in just a few minutes with little to no maintenance required.
- 200+ Native Connectors: Instantly connect to applications, databases, file storage options, and data warehouses with our fully-managed and always up-to-date connectors, including BigQuery, Redshift, Shopify, Snowflake, Amazon S3, Firebolt, Databricks, Salesforce, MySQL, PostgreSQL, and Rest API to name just a few.
- Python Support: Have a data source that requires custom code? With Rivery’s native Python support, you can pull data from any system, no matter how complex the need.
- 1-Click Data Apps: With Rivery Kits, deploy complete, production-level workflow templates in minutes with data models, pipelines, transformations, table schemas, and orchestration logic already defined for you based on best practices.
- Data Development Lifecycle Support: Separate walled-off environments for each stage of your development, from dev and staging to production, making it easier to move fast without breaking things. Get version control, API, & CLI included.
- Solution-Led Support: Consistently rated the best support by G2, receive engineering-led assistance from Rivery to facilitate all your data needs.
Which is Better: ETL or ELT?
Cloud data warehouses have given rise to a new frontier in data integration, but choosing between ETL and ELT depends on a team’s needs.
Although ELT offers exciting new advantages, some teams will remain with ETL because the method makes sense for their particular deployment, legacy infrastructure or not.
ETL’s data pipeline creates a safer process for handling sensitive data and meeting compliance standards.
Whatever the choice, data teams across the spectrum are finding success actuating their integration strategies by harnessing a data integration platform.
Learn More about ETL vs ELT
Interested in learning how Rivery can help you choose between ETL and ELT for your specific data needs? Speak to a Rivery data expert today and we’ll help you solve your most complex data challenges.
FAQs
ETL: extract, transform, load and elt: extract, load, transform are processing methods for data integration. The key difference lies in the order of processing. In ETL, data is extracted from the data source, transformed into a suitable format, and then loaded onto the data warehouse or data lake. In ELT, data is extracted and loaded onto the target destination before it is transformed into the desired format in the data warehouse or data lake.
The choice between ETL and ELT depends on your specific needs and resources. ETL is often preferred when dealing with smaller volumes of data, where data quality and cleansing are critical before loading, or when the target database isn’t powerful enough to handle complex data transformations. Elt, on the other hand, is typically chosen when dealing with larger volumes of data, where the speed of loading data is crucial, and when the target database has the processing power to handle transformations.
Yes, there can be significant performance differences between ETL and ELT, particularly when dealing with large volumes of data. ELT can often be faster because it takes advantage of the processing power of modern databases to perform transformations. However, ETL can provide better performance when the transformations are complex and the target database isn’t powerful enough to handle them efficiently.



Minimize the firefighting. Maximize ROI on pipelines.

