Logic - Overview
- 3 Minutes to read
- Print
- DarkLight
- PDF
Logic - Overview
- 3 Minutes to read
- Print
- DarkLight
- PDF
Article Summary
Share feedback
Thanks for sharing your feedback!
Introduction
The term "Logic Rivers" originates from their reliance on a logical data model that outlines the configuration of data elements and the associations among different Rivers.
Logic Rivers serve as a tool for workflow orchestration and data transformations, and they can accommodate other Rivers.
SQL can be employed for in-warehouse transformations, while Python can be used for more complex scenarios.
Rivery's Orchestration provides support for branching, multi-step processes, conditional logic, loops, and other features, making it easy to design complex workflows.
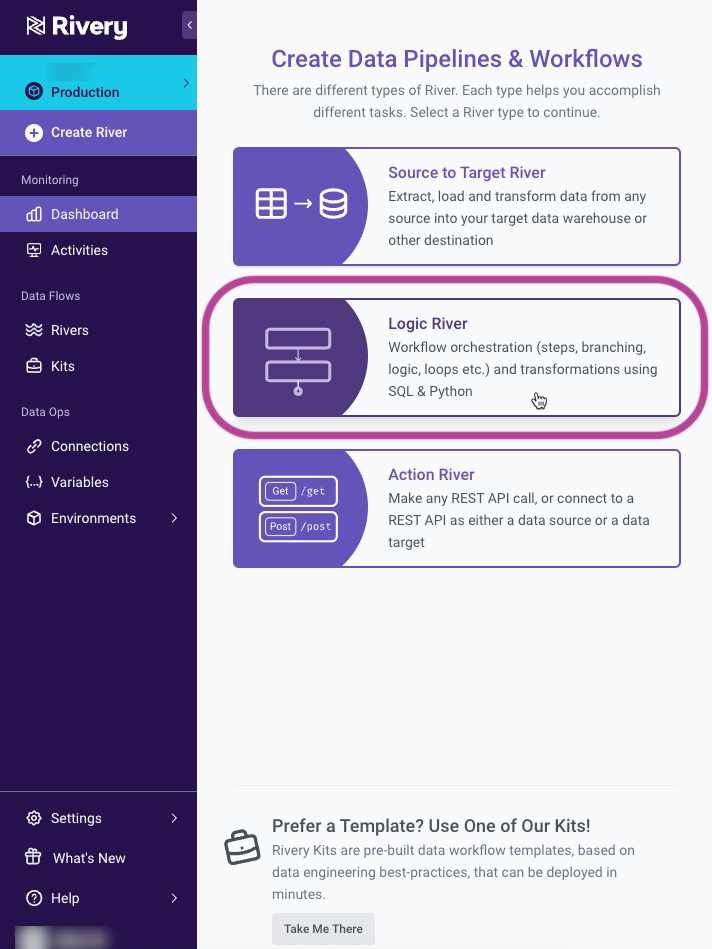

You can use Logic Rivers for orchestration of your data workflow and to build your data warehouse using in-database transformations.
In a Logic River, users can orchestrate a series of logical steps without any coding. Each step can perform a different type of process on your data.

- SQL / DB Transformation: Run an in-database query or a custom SQL script using the syntax compatible with your cloud database, and then save the results into a table, file, DataFrame, or variable.
- River: Trigger existing River within your account. This could be a Source to Target River that you wish to coordinate alongside other Source to Target Rivers and transformation steps.
- Action: Make any custom REST call.
- Python: Allows for quick and easy data manipulation using Python scripts.
Once you create your first steps of a Logic River, you can wrap them in a container to organize your workflow. Containers enable you to group different logic steps together to perform the same action on them. For example, you can group multiple Data Source to Target Rivers (this is the ingestion river type) together in a single container and set the container to run in parallel, so that all jobs are kicked off at the same time. When all steps in the container have completed successfully, the following step will run.
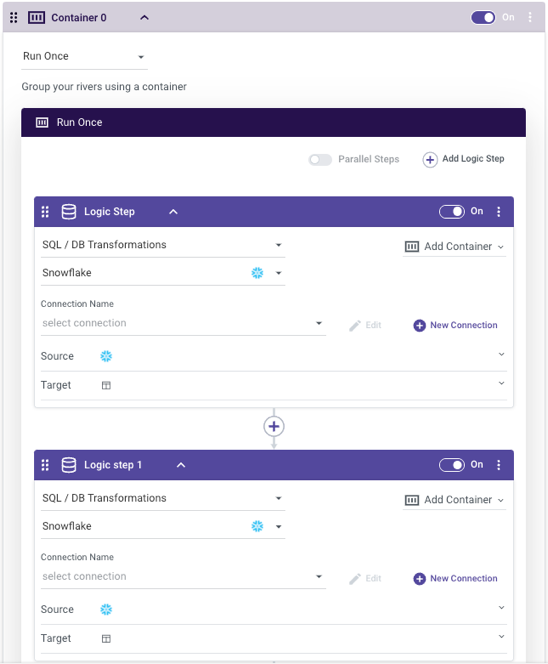
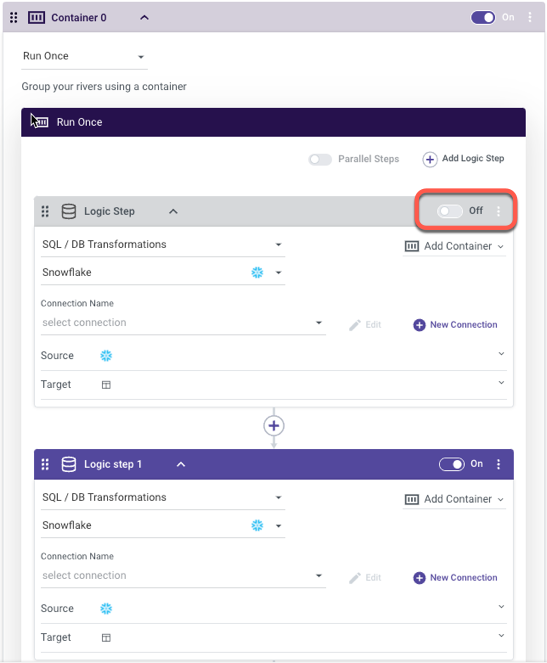
Another user-friendly feature is the ability to disable any container or logic step in the workflow. This makes the building of a Logic River a truly modular process, as I can disable longer running parts of my river while developing and testing a different step.
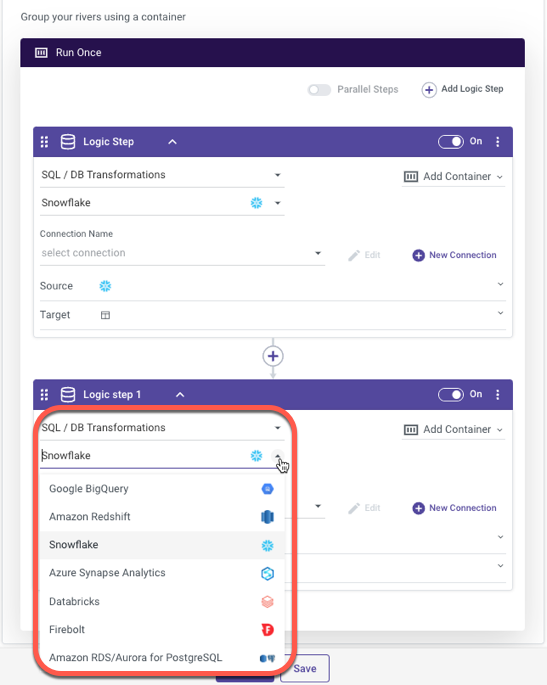
When a logic step is set to 'SQL / Script,' you can perform data transformations using the resources of a cloud data database. This step type allows for complete flexibility and customization of queries to cleanse, prep or blend data (supported cloud databases include: Google BigQuery, Amazon Redshift, Snowflake, Azure Synapse Analytics, Amazon RDS/Aurora for PostgrSQL, Azure DataLake).
The results of your source query can be stored into a Database Table, Variable, DataFrame, and File Storage.
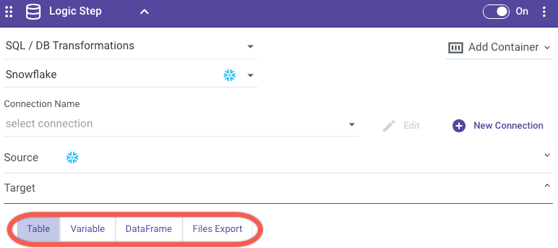
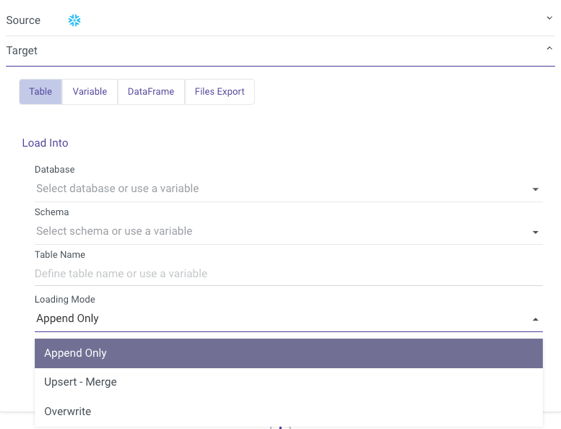
When saving into a database table, all you have to do is specify the desired table name and location for the query results to land. Rivery supports multiple loading modes (Overwrite, Upsert-Merge, and Append). This takes no initial setup on the database side - if a table doesn’t yet exist, Rivery will create it on the fly. No need to pre-define your table metadata beforehand!
BUT…THERE'S MORE!
In addition to enabling the orchestration of the ingestion and transforms of an entire data pipeline, Logic Rivers have a few 'tricks up their sleeve' that make for the user-friendly development of dynamic and generic data processes.
Logic Rivers provide the ability to store data values into variables and use them throughout the workflow. Variables can be stored as River specific Variables or Environment Variables.
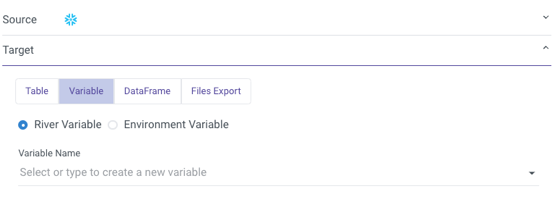
In addition to containers allowing for organization and grouping of logic steps, they can be used as a mechanism for looping or adding conditional logic to your river. Since the variable values themselves are recalculated every time the river runs, it is a truly dynamic way to develop a data pipeline.
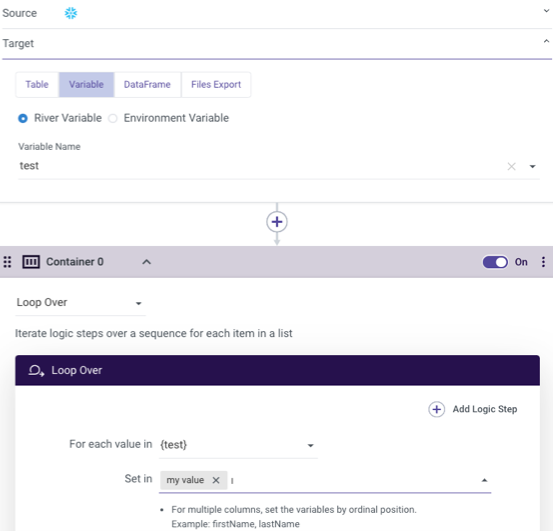
Another use case for using variables in a logic river:
By attaching the following variables:
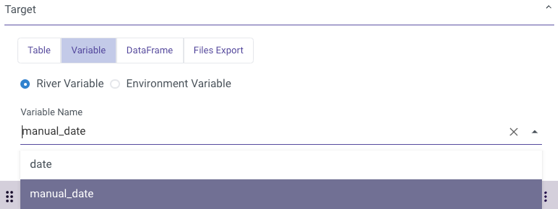
with the following values:
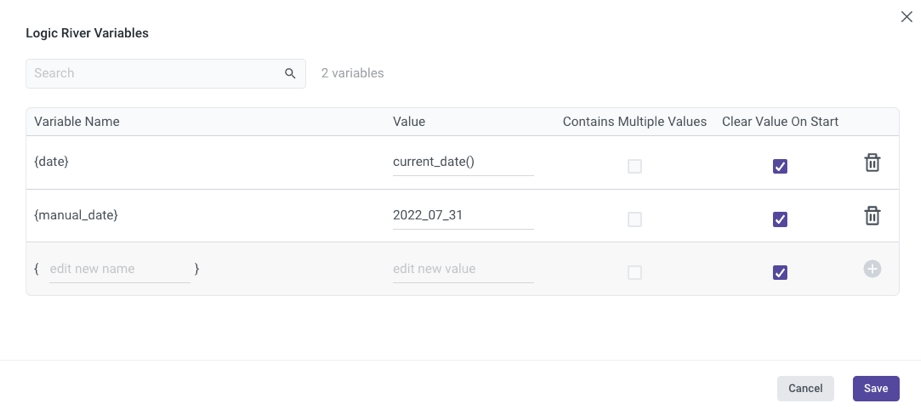
One can use the date variable in the SQL script and target name:
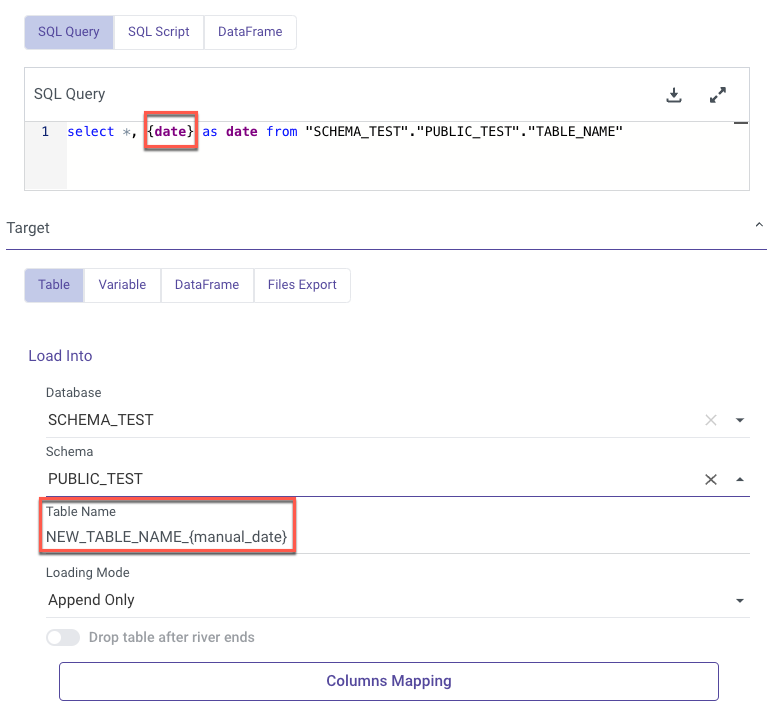
Here is an example of the received target automapping:

Was this article helpful?