Amazon S3 as a Target
- 2 Minutes to read
- Print
- DarkLight
- PDF
Amazon S3 as a Target
- 2 Minutes to read
- Print
- DarkLight
- PDF
Article Summary
Share feedback
Thanks for sharing your feedback!
This tutorial will show you how to set up Amazon S3 as a Target.
Prerequisites
- If you're new to Amazon S3, use our step-by-step guide to create an S3 bucket and get connected.
Setting up Amazon S3 as a Target Procedure
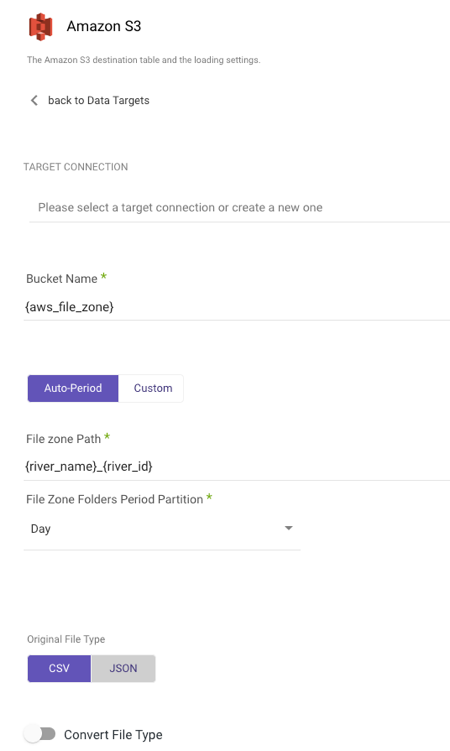
After you've established a connection, choose your Target Connection.
Select the type of partition granularity:
- Auto-Period
- Custom
By default, the Auto-Period option allows for data partitioning into periods as granular as minutes. However, if additional partitioning is required beyond the default granularity, users can select the Custom option.

Auto-Period Partition
a. Type in your Bucket Name.
b. Enter the FileZone path from your S3 storage. Here's an example:
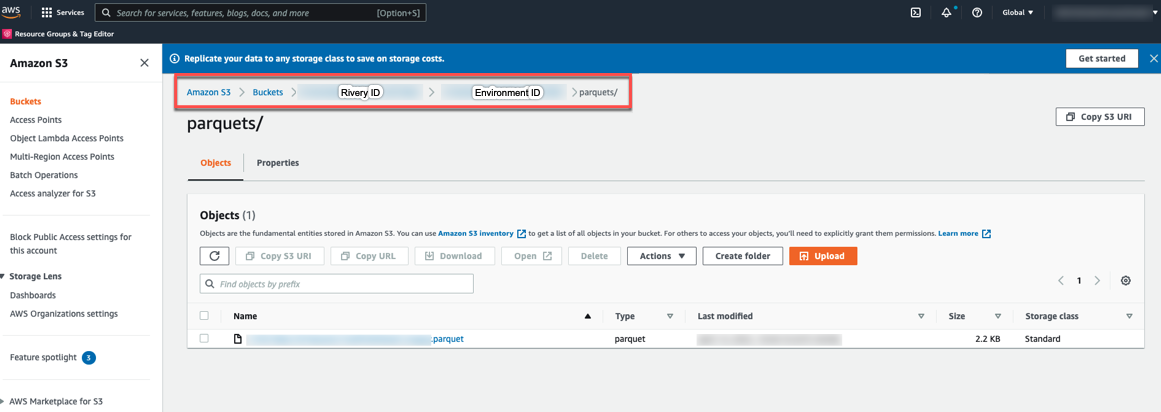
- Set the period partition timeframe for a FileZone folder.
Custom Partition
Custom partition granularity path allows you to specify the exact partitions that are used when loading data. This can help optimize the performance of your Rivers.
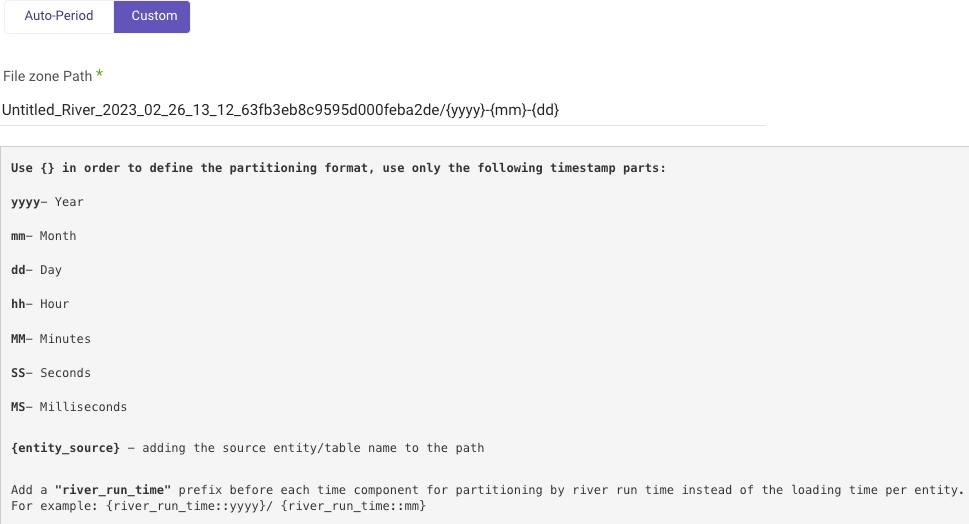
To configure custom partition granularity path:
a. Type in your Bucket Name.
b. Enter the Custom FileZone Path from your S3 storage.
Using the template:
{river_name}_{river_id}/{yyyy}{mm}{dd}_{hh}{MM}{SS}{MS}/{entity_source}.
c. Specify the granularity variables:
- yyyy - The numerical value representing a specific year (4 digits).
- mm - The month's numeric identifier within a calendar year (01, 03, 05, 12 ,etc).
- dd - The corresponding day on the 7 day week (1, 2, 7, etc).
- hh - The corresponding hour on the 24-hour clock (9, 10, 12, etc)
- SS - Seconds
- MS - Milliseconds
- entity_source - Using entity names for multi-tables Sources is beneficial as it allows for the creation of a separate folder for each table within the entity.
- entity_target - Including the name of the Target entity/table in the path.
- river_run_time - To partition by River run time rather than loading time per entity, use the "river_run_time" prefix before each time component. This means adding "river_run_time" before the year, month, day, or any other time component you want to use.
See example 3 below.
Please Note:
You are not required to input all variables, rather just input the ones that are most effective for your needs.
The option is only available for the sources listed below:
- Adobe Analytics
- Airtable
- App Store Connect - Sales
- Bing Ads
- Bluesnap
- Delta projects
- Display & Video 360
- DoubleClick Campaign Manager
- Facebook Ads
- Google Ad Manager
- Google Ads
- Google Analytics
- Google Cloud Storage
- Hasoffers
- Hubspot
- Linkedin Ads
- Mixpanel
- Moat Analytics
- MySQL
- Oracle
- Outbrain
- PostgreSQL
- Salesforce
- Sprinklr
- SQL Server
- Stripe
- Tiktok
- Twitter Ads
- Verta Media
Here are some examples
1. Template input: {river_name}_{river_id}/{yyyy}-{mm}-{dd}_{hh} —>
s3://demo-bucket/mysql_to_S3_63b6a63a109fe00013417086/2023-01-05/items/d0e94c9a90d34b669309d36c5b1abc12_mysql_items_7615f00000PFqjiAAD_7525f00000Dfo2C.csv
2. Template input: {river_name}_{river_id}/{yyyy}-{mm}-{dd}_{hh}:{MM}:{SS}:{MS}/{entity_source} —>
s3://demo-bucket/google_ad_manager_to_S3_63b6a63a109fe00013417086/2023-01-05_20:30:12:13/line_items/c0e94c9a90c34b669309d36c5b1abc12_ad_manager_line_items_7515f00000PFqjiAAD_7525f111110Dao2C.csv
3. Template input: Salesforce/{river_run_time::yyyy}{river_run_time::mm}{river_run_time::dd}_{river_run_time::hh}{river_run_time::MM}{river_run_time::SS}{river_run_time::MS}/{entity_source} —>
s3://demobucket/Salesforce/20230105_20301213/leads/d0e94c9a90d34b669309d36c5b1abc12_salesforce_Lead_7615f00000PFqjiAAD_7525f00000Dfo2C.csv
d. Rivery will automatically set your data into partitions of the specified varialbes when loading data.
- Select the original file type, then toggle to true if you want to convert the file to a Parquet file type.
- Any Source to Target River can now send data to your S3 bucket.
Parquet File Type
Rivery allows you to convert CSV/JSON files to Parquet directories.
Parquet is an open source file format designed for flat columnar data storage. Parquet works well with large amounts of complex data.
Toggle to true to convert your original file type to a Parquet:
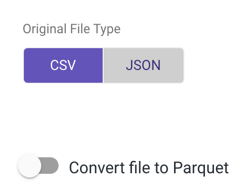
Please note that Webhook and Storage Files (with the exception of Amazon S3 and Email) are not currently supported but will be in the near future.
Was this article helpful?