





















Load Data from (Almost) Any Source into Parquet Files

Intro
Converting data into Parquet format is a non-trivial task. Using Python’s Pandas library makes it pretty simple, but we just made it easier. You can now save data from most sources into Parquet files in S3 as part of your data pipelines with Rivery – the leading SaaS ELT & workflow orchestration platform.
What is Parquet?
Apache Parquet is an open source, columnar file format that is optimized for storing, retrieving and querying information at scale.
Unlike row-based storage mediums like CSV’s, Parquet files store all of the relevant header information as a single column, with subsequent columns containing the actual metadata.
Parquet files also contain auxiliary tables that reference the relevant schemas and columns when querying at scale, to help find information faster using less computational resources. Syntactically, it’s similar to column-based file formats in hadoop such as ORC and RCFile.

What is Rivery?
Rivery is a Saas ELT tool that lets you ingest data from 200+ natively supported and custom API sources, load them to popular cloud data warehouses such as Snowflake, BigQuery and Redshift, and transform/orchestrate data processes using push-down SQL, Python, Snowpark, and REST API’s.
The Process
Rivery’s new “Convert File to Parquet” feature for S3 buckets lets you convert any JSON or CSV file (from most sources) into a Parquet file stored in S3 – at the click of a button.

This feature is available for single source, multi-table, and predefined reports when using Amazon S3 as a target.
Why use Parquet?
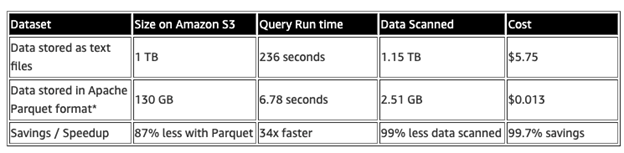
Parquet files have numerous advantages over traditional row-based file types, especially when it comes to bulk data.
- Parquet files are optimized for query performance.
When querying columns in traditional row-based datasets, one has to generally scan all of the columns for a particular match and then iterate through the rows based on the filter.With Parquet, all of the headers are stored in “row groups”, with the metadata itself contained in a “footer”.The relevant row groups that are not explicitly written into the query are thus never scanned at execution. This results in a considerable performance improvement over large datasets. - Highly efficient in data compression and decompression.Parquet files are highly compressible due to their structure and can be easily decoded back into the original format.

4. Better handling of nested data structures.Deeply nested data structures are more efficiently represented in parquet due to the columnar structure saving the relationships between parent and child fields in a single column.
If you need to convert your data from almost any source, such as databases, apps, csv files, and more, into Parquet files, schedule a call with a data expert and we’ll show you how easy it is to do with Rivery.



Minimize the firefighting. Maximize ROI on pipelines.

