





















Rivery CLI: Unlock the Full Potential of DataOps

As a true DataOps platform, Rivery gives our customers absolute control over their data, all while enhancing flexibility and agility. It’s one of the core reasons why fast-moving data teams turn to Rivery. And now, with the Rivery CLI (command-line-interface), our customers can take the power, speed, and scalability of DataOps to a new level.
Read on to learn how Rivery CLI can unlock new dimensions and efficiencies in your data operation.
What is the Rivery CLI?
The Rivery CLI enables data engineers and other data developers to remotely execute, edit, deploy, and manage data pipelines via CLI and convert data pipelines into infrastructure as code (IaC). The Rivery CLI modifies and stores data pipeline configurations as YAML configuration files. Developers can push these YAML files into the Rivery platform to update the corresponding data pipelines.
Learn how to set up the Rivery CLI and start using it in this step-by-step walkthrough.
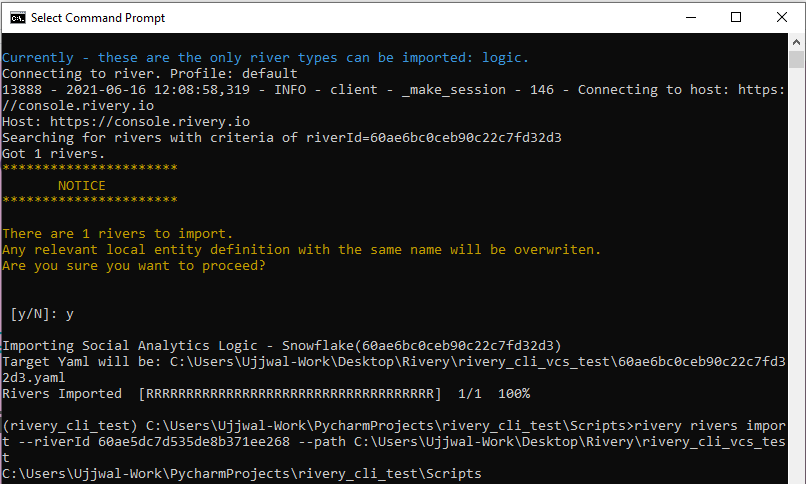
The Rivery CLI empowers developers to create, edit, and save Logic Rivers configurations in a simple text editor. This allows teams to sync pipeline logics – such as SQL-based transformations – within version control systems (VCS) such as GitHub. With this Git compatibility, teams can potentially implement DevOps practices, including track changes, continuous integration and continuous deployment (CI/CD), and code reversion.
Watch this video to see how to set up Git integration for Rivery CLI in just a few steps.
Rivery CLI: Make Your Data Operation Faster & More Efficient
In a landscape where 63% of business users cannot gather insights on their required timeframes, the speed and agility of Rivery CLI offer a real competitive advantage. With Rivery CLI, organizations can deploy data infrastructure faster and more efficiently to meet rapidly changing organizational data needs.
Rivery CLI streamlines the DataOps process in several ways:
- Launch data pipelines & data infrastructure via code – Remotely launch pre-built data pipelines for 150+ data sources, add custom data sources with Rivery’s Custom API, schedule data ingestion, build Logic Rivers, and more, all from a command-line interface.
- Enhance data transformations – Access Rivery’s transformation capabilities via code. Maintain SQL transformations in Git, unlock track changes, bulk updates, and script-based modification.
- Implement version control – Manage all logics and transformations in version control systems to maintain total command over and visibility into the data product delivered to stakeholders.
- Incorporate development best-practices – With Git integration, optimize production cycles with agile development, and apply DevOps functions to pipeline code, such as CI/CD, debugging, and staging environments.
- Revise & reinstate code – Store all versions of transformations and Rivery Kits for revision and reversion.
Rivery CLI enables data developers and data engineers to access and implement the Rivery platform in the format they feel most comfortable with: code. At the same time, data analysts or even non-technical personnel can still build data infrastructure using Rivery’s point-and-click UI in parallel to data engineering efforts.
Developers can then edit the infrastructure created in the UI with Rivery CLI, allowing total synergy between the data initiatives of technical and non-technical teams. This hybrid DataOps framework that leads to quicker outcomes and stronger results for teams across an organization.
Use Cases: Rivery CLI in Action
Customers can apply Rivery CLI in a number of diverse ways, but the following use cases are some of the most popular we’ve encountered among our user base.
Remote Execution
Building off of the functionality of the Rivery API, the Rivery CLI enables remote river execution in a Python framework. Using the run rivers CLI command, customers can embed data pipelines built in Rivery’s point-and-click UI into Python scripts, external schedulers, or traditional ETL tools such as Airflow. This makes data developers, and ETL workflows, more efficient and flexible.

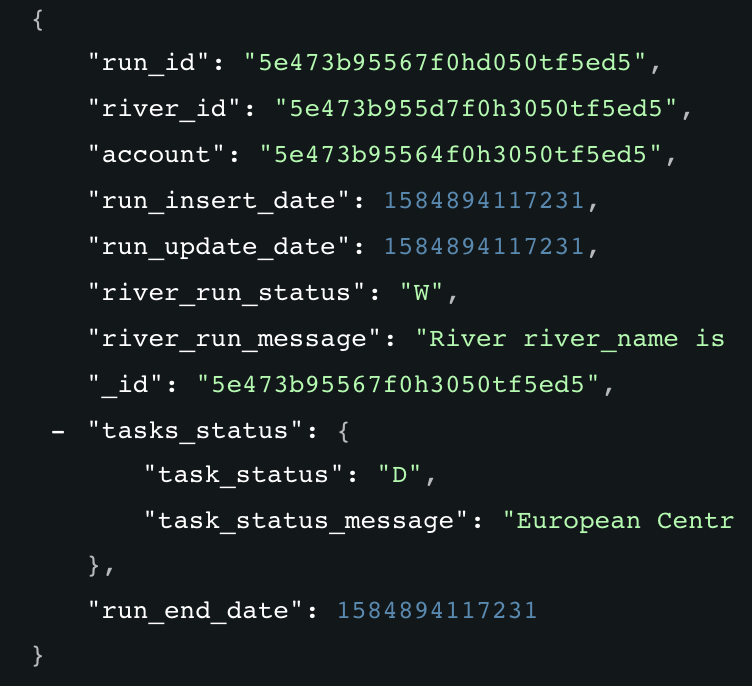
Status Check
An effective ETL/ELT workflow must confirm successful pipeline runs, identify failed pipeline runs, and log execution stats. With the CLI’s run status command, customers can retrieve the status of a pipeline and log essential metrics of pipeline runs in combination with Rivery API’s check_run call. This allows customers to pull the runs’ logs for a better perspective on pipeline performance. These metrics include timestamps, completion, potential error messages/warnings, and more. This speeds up data projects and allows engineers to verify the integrity of existing and updated data processes.
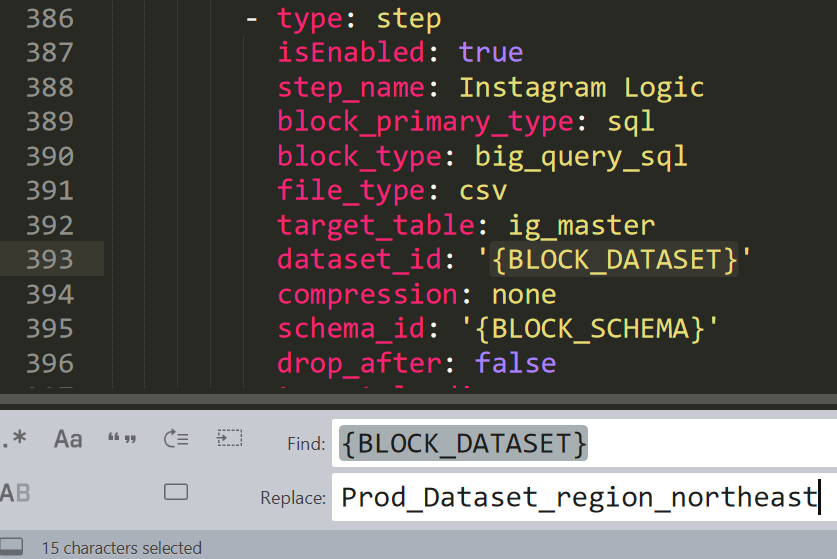
Bulk Updates
Customers can easily push bulk updates to Logic Rivers with the Rivery CLI. By harnessing The Rivery CLI, customers can enable bulk updates using the YAML configuration files corresponding to each Logic River.
This works for all kinds of updates, including:
- Recently changed databases
- Renaming a column/variable
- Editing one small component of an SQL query, but applying it to all steps
Customers can update Logic River YAML files via a text editor, and then push these changes to VCS tools like GitHub or directly back to a Rivery account. Bulk updates eliminate a significant amount of manual labor and allow teams to focus more cerebral tasks.
Rivery CLI: A Nimble, Code-Based Tool to Make Dev Life Easier
With Rivery CLI, data developers and data engineers can now supercharge the speed and execution of data operations using a flexible command-line interface. Rivery CLI gives dev-oriented personnel a nimble, code-based alternative to Rivery’s point-and-click UI by utilizing the Infrastructure as Code (IaC) methodology. This enables devs to work with the tools they prefer, and opens the door to new optimizations to the DataOps process.
Rivery CLI is officially live – try the feature now and tell us what you think!
Interested in learning more? Join us Wednesday, July 14 for a live webinar, where we’ll walkthrough Rivery CLI in full detail. Save your spot here!



Minimize the firefighting. Maximize ROI on pipelines.

