





















DataOps combines technology, processes, principles, and personnel to automate data orchestration in your business.
DataOps offers a flexible data framework that provides the right data, at the right time, to the right stakeholders. It performs this by merging agile development, DevOps, personnel, and data management technology.
In simple terms, DataOps enhances the efficiency, quality, and reliability of data analytics by applying agile and DevOps methodologies to data processes.
The 4 key objectives of DataOps include:
Accelerate data delivery: DataOps can reduce the time taken to deliver data insights from raw data to actionable information. As a result, organizations can achieve faster time-to-value.
Enhance data quality: High-quality data is needed for trustworthy analytics. DataOps implements rigorous testing, validation, and monitoring to maintain data accuracy.
Improve collaboration: DataOps helps break down silos and aligns data activities with business goals. It achieves this by building better communication and collaboration among data engineers, data scientists, analysts, and other stakeholders.
Increase agility: DataOps brings agility to data processes, enabling organizations to adapt quickly to changing business requirements and data sources.
DataOps Framework
The DataOps framework is a broad approach that integrates various methodologies and practices to optimize data management and analytics workflows within your organization.
The DataOps framework consists of five key components:
1. Data Orchestration
Data orchestration is the automated arrangement, coordination, and management of data processes and workflows. It guarantees you collect, process, and deliver data across various systems effortlessly.
The main elements of data orchestration include:
- Workflow automation: Data orchestration automates the scheduling, execution, and monitoring of data tasks to reduce manual intervention and boost efficiency.
- Data integration: Data orchestration combines data from various sources—databases, APIs, files—into a unified view. This ensures consistency and accessibility.
- Error handling: Data orchestration uses mechanisms to detect, log, and resolve errors during data processing. As a result, this ensures complete data integrity.
- Scalability: Data orchestration ensures processes scale to handle increasing data volumes and complexity. It achieves this without compromising performance.
2. Data Governance
Data governance uses policies, standards, and practices to guarantee data’s accuracy, quality, and security. In turn, it provides a structured approach to managing data assets and compliance with regulatory requirements.
The key elements of data governance include:
- Data quality management: Data governance ensures data is accurate, complete, consistent, and reliable.
- Data security: Data governance protects data from unauthorized access and breaches through encryption, access controls, and auditing.
- Data lineage: Data governance tracks the origin, movement, and transformation of data across the data lifecycle. By doing so, it ensures transparency and traceability.
- Compliance: Data governance complies with regulatory requirements and industry standards—such as GDPR, HIPAA, and CCPA—ensuring data practices meet legal and ethical guidelines.
3. CI/CD Pipeline
The CI/CD (Continuous Integration/Continuous Deployment) pipeline in DataOps enables the automated testing, integration, and deployment of data applications and analytics. It ensures rapid and reliable updates and releases, which improves the responsiveness of data teams.
The key elements of CI/CD pipeline include:
- Continuous integration: The CI/CD pipeline integrates code changes from multiple contributors into a shared repository. It follows this with automated testing to detect issues early.
- Continuous deployment: The CI/CD pipeline also automates the deployment of tested code to production environments, ensuring new features and updates are delivered reliably.
- Automated testing: The CI/CD pipeline includes unit tests, integration tests, and end-to-end tests to ensure the correctness of data applications.
4. Data Observability
Data observability concentrates on the ongoing monitoring and analysis of data systems to detect and address issues proactively. By doing so, it delivers visibility into data workflows to enable teams to maintain data quality and system reliability.
The key elements of data observability:
- Monitoring: Data observability continuously tracks the health and performance of data pipelines, infrastructure, and applications.
- Alerting: Data observability notifies teams of anomalies, errors, or performance degradation in real time, enabling prompt response and resolution.
- Metrics and dashboards: Data observability provides visual insights into key performance indicators (KPIs) and operational metrics.
5. Automation
DataOps software reduces manual intervention by using tools and scripts to perform repetitive tasks. This boosts efficiency, consistency, and accuracy in data processing and analytics operations.
The key elements of automation include:
- Task Automation: Routine tasks—such as data extraction, transformation, loading (ETL), and reporting—will be automated.
- Workflow automation: Automation streamlines complex workflows by using dependencies, triggers, and scheduling with the help of DataOps management.
- Self-service: Automation enables users to access and analyze data without relying on IT. It achieves this through user-friendly interfaces and automated query generation.
Benefits of DataOps
This is the mission of DataOps is to create agile, scalable, and controllable data workflows for DataOps teams.
DataOps feeds data consumers, internal and external stakeholders, and customers the data they need, when they need it. This provides companies with several competitive edges in the data economy, including:
1. Data Democratization
From executives, to SDRs, to warehouse workers, DataOps unlocks data for employees across the entire company. By enriching every part of an organization with data, DataOps enhances results, ROI, and competitiveness across the organization.
2. Faster Speeds to Data Insights
DataOps equips stakeholders with critical insights faster, allowing stakeholders and teams to move with superior speed in a rapidly-moving market.
3. Incisive Decision Making
DataOps puts the right data into anyone-and-everyone’s hand, leading to more informed and effective decision making at every level of the company.
4. Improved Data Productivity
The agile framework of DataOps enables data professionals to make quick, targeted data pipeline deployments and changes, eliminating manual and cumbersome processes.
This boosts productivity not only for the data team, but also for data consumers, who no longer need to wait for data to complete tasks.
5. Sharper Data Insights, Sharper Results
The DataOps framework builds feedback from data consumers into pipeline development, producing the customized insights that stakeholders need to increase revenue.
How Does DataOps Work
DataOps works by combining agile development, DevOps, and lean manufacturing principles into data processes. In turn, this delivers efficient, reliable, and high-quality data operations.
Here’s a breakdown of how DataOps works:
- Planning: DataOps determines data needs, quality standards, and compliance requirements. It also defines KPIs and assigns resources.
- Developing: DataOps automates data ingestion from various sources before placing them into a centralized repository.
- Building: DataOps automates workflows to manage data movement and processing efficiently.
- Testing: DataOps uses automated testing to ensure data pipeline reliability and accuracy.
Deploying: DataOps automates the deployment of data pipelines and analytics applications to production environments.
Who Leads DataOps?
By design, DataOps teams will include temporary stakeholders during the sprint process. However, a permanent group of data professionals must power every DataOps team, and often include:
- The Executive (CDO, CTO, etc.) – The executive drives the team to produce business-ready data for data consumers and leadership. He/she guarantees the security, quality, governance, and life cycle of all data products.
- The Data Steward – The data steward builds a data governance framework for the organization’s data systems, in order to manage data ingestion, storage, processing, and transmission. This framework forms the backbone of the DataOps initiative.
- The Data Quality Analyst – The data quality analyst improves the quality and reliability of data for consumers. Higher data quality translates into better results and decision making for data consumers.
- The Data Engineer – The data engineer builds, deploys, and maintains the organization’s data infrastructure, such as all data pipelines, including SQL transformations. The data infrastructure ingests, transforms, and delivers data from source systems to the right stakeholder.
- The Data/BI Analyst – The data/BI analyst manipulates, models, and visualizes data for data consumers. He/she discovers and interprets data so stakeholders can make strategic business decisions.
- The Data Scientist – The data scientist produces advanced analytics and predictive insights for data consumers. These enhanced insights enable stakeholders to improve decision making.
Are DataOps and Data Operations the Same?
DataOps is a collaborative data management practice whose goal is faster delivery of insights and data by automating the data delivery design and management. The decision-making data teams and applications get the data at real-time speeds.
On the other hand, data operations has a different, much wider approach to data. Looking at the data and the data pipeline, it considers the data availability, operational needs, the hybrid infrastructure where data resides, and security. The process also covers the integrity and performance that maximizes the data potential.
The goal of data operations is to maximize the value of the data and the pipeline. The infrastructure within the pipeline requires tuning, securing, testing, performance monitoring, and much more.
What is Data Operations Management?
Data management is a challenging task for all data teams and data scientists. Data management ensures acquiring, validating, storing, and protecting data in a certain standardized way.
At the same time, DataOps is a collaborative data management practice that improves the integration, communication, and automation of data flows.
Recognized as an innovation trigger, DataOps allows the maximization of the data business value and infrastructure. There has been a rise in DataOps to boost the data processes of the business.
Agile development, treatment of data as code, automation of data processes, friendly application development, minding storage, and efficient data distribution are just some of the best data management practices with DataOps.
How does a DataOps Organization work?
DataOps is a methodology that brings together data engineers and data scientists with DevOps teams. This collaboration is essential to the success of the organization. The process-oriented methodology optimizes the development and delivery of data analytics. DevOps teams collaborating with data teams are focused on improving the communication, integration, and automation of the data flows between the data managers and consumers throughout an organization.
A well-established DataOps organization ultimately streamlines the design, development, and maintenance of applications founded on data and data analytics. In turn, the “hierarchy” improves how data is managed and products are created to further align the improvements with the business’s goals.
Issues DataOps Can Solve
DataOps is the perfect methodology to streamline the operational processes within organizations and help with the following issues:
- Limited collaboration: DataOps workflows improve cross-team collaboration, integrating the functionalities of different data-focused teams.
- Resolving bug issues: DataOps is great for managing incidents. Fixing data defects and bugs is a vital business function that DataOps workflow makes possible.
- Maximize response time: Responding to development requests (from users and management) faster. Data teams gain insight into the recent data effects on the existing data flow.
- Setting goals: When properly implemented, DataOps delivers insight into the performance of data systems in real-time. This is a valuable asset to both management and dev teams. It allies relevant decision-makers in adjusting or updating business goals.
- Enhancing business analytics: The quintessential goal of DataOps is to supplement (not replace) data hubs, i.e., data infrastructures like data lakes and warehouses. DataOps modifies the typical data hub to meet the unique and evolving demands of business analytics teams.
DataOps Tools
There is an array of versatile DataOps on the market today. We have shortlisted some of the most popular DataOps tools to choose from and ensure your data flows align with your business goals.
- Rivery: A powerful, fully-managed data management tool that helps businesses scale their DataOps workflows from start to finish. Rivery is a serverless, SaaS DataOps platform that helps businesses of all scopes and sizes consolidate, orchestrate, and easily handle data sources (internal and external).
- Databricks: A data management platform best used for unifying data warehouses. It is a software platform that helps businesses consolidate data analytics across the business, data science, and data engineering.
- Tengu: It’s a DataOps orchestration tool for data and pipeline management.
- Census: An operational analytics platform specialized in Reverse ETL.
- DataKitchen: A platform for data automation and data observability for orchestrating end-to-end data pipelines.
Whichever DataOps tool you choose, make sure it caters to your primary business goals, is not difficult to set up, and won’t cause any additional costs.
Agile: The Speed Flexibility of DataOps
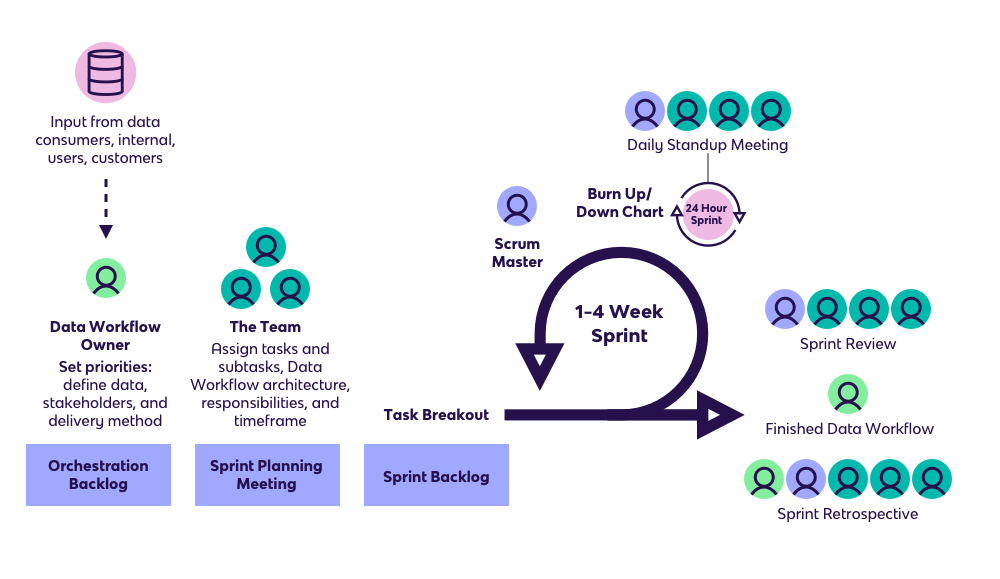
In DataOps frameworks, the principles of agile development are used to build data infrastructure, such as data pipelines. On a granular level, data infrastructure is just code, or “infrastructure as code” (IaC). IaC is the “software product” in agile terminology.
Within a DataOps framework, cross-functional teams execute “data sprints” that design data models and deliver analytics for targeted stakeholders. Each team is composed of data managers (data engineers, BI managers, etc.) and data consumers (salespeople, leadership, etc.).
Feedback from data consumers is incorporated continuously within the sprint process to quickly improve and update data assets.
What is the Difference between DevOps and DataOps?
Both originating from agile project management, DataOps and DevOps are two distinct methods that often get confused.
DevOps and DataOps both utilize Agile methodology to promote collaborative learning and efficiency.
Although they both work around bringing clarity and focus, their main business areas are completely different. Nonetheless, they do have some similarities, as shown in the table below:
DataOps vs. DevOps Similarities | DataOps vs. DevOps Differences |
Increased Collaboration | Outcome |
Agile Connection | Feedback |
Iterative cycles for value | Testing |
Workflow |
The difference between DevOps and DataOps is that DevOps combines software development and IT operations to automate software deployments, while DataOps automates the ingestion, transformation, and orchestration of data workflows.
DevOps concentrates on improving software development and IT operations through short and swift feedback loops, continuous integration, and deployment. It uses CI/CD pipelines, containerization, and configuration management.
Meanwhile, DataOps highlights data acquisition and management by incorporating Lean principles to maintain real-time data pipeline connectivity. It uses tools for data integration, orchestration, and governance to supply useful data.
Traditionally employed in software production, DevOps combines software development (Dev) with IT operations (Ops) to speed up the time-to-release of high-quality software. DevOps merges the processes of building, testing, and deploying software into a single automated practice.
Although DataOps derives its name from DevOps, DataOps is not simply DevOps for data. Instead of automating software deployments, DataOps automates and unifies the ingestion, transformation, and orchestration of data workflows.
One place where both methods work parallel is the iterative cycles. These are used to produce fast results and feedback to proceed with the process should the data meet the basic needs.
There is also an increased collaboration on both sides by prioritizing the key performance indicator. The collaborative data management practice, DataOps, enables the development of valuable insights to goals by working with business users, while DevOps quality assurance teams aim to develop better software.
Testing | Workflow | Feedback | Outcome | |
DataOps | Because the outcome is uncertain, normal testing and additional validation are required to ensure the accuracy of the information. | In addition to creating new pipelines, it's important to focus on ensuring data accuracy at any time by constant data pipeline monitoring. | End-user feedback is required to validate if the delivered solution meets the expectations and offers the best information | Deliver business information to users by focusing on creating data pipelines |
DevOps | With the outcome defined in advance, the testing process is a rather straightforward evaluation to check if the application behaves as expected. | Use frequent deployments and releases to define application features in the development stages. | End-user feedback is valued but not required if the delivered solution is satisfactory for the customer. | Deliver new functionality to users by creating software applications. |
DataOps unlocks key advantages by harnessing the practices of DevOps, including:
1. Source Control
A centralized repository of all data ingestion processes, transformation logic, pipeline source code, and data delivery monitoring, in version control systems such as GitHub.
2. Continuous Data Integration
Automatically merge developer source code with live pipelines to avoid “integration hell.”
3. Separate Test & Production Environments
Evaluate pipelines before launch in a test environment identical to production. Easily push changes live after Q&A diagnostics.
4. Continuous Delivery
Continually deploy incremental but frequent code updates to the production environment automatically.
DataOps Framework
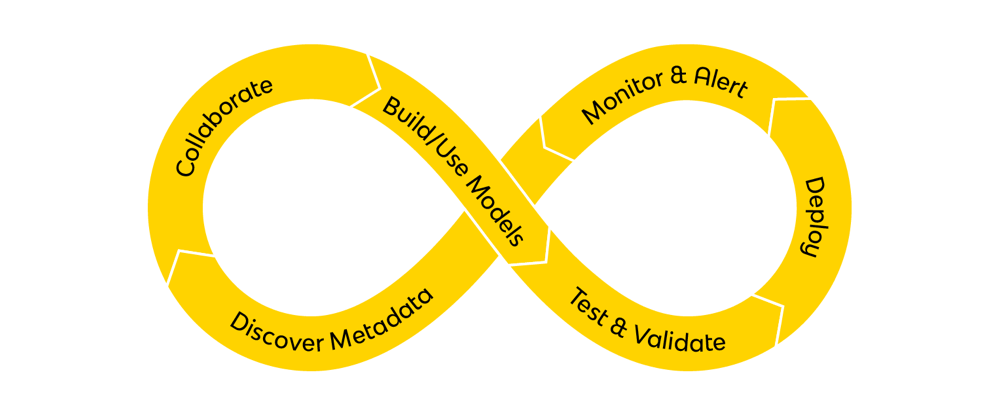
DataOps team members can develop data infrastructure in separate but nearly identical environments, and push changes live with point-and-click functionality after a predefined testing process.
DataOps, like DevOps, relies on automation to eliminate manual tasks and IT processes, for example:
- Data orchestration automates entire data workflows, from data ingestion to transformation, to delivery
- Auto-syncing developer source code with main repository
- Data pipelines pushed live into production with one-click deployments
Differences in Processes and Outcomes
DevOps and DataOps may share the approaches and framework, but their processes and outcomes differ. DevOps focuses on fast software delivery through customer-guided improvements. DataOps’ focus is on data stream creation for the delivery of information to end users.
DataOps is known to help align business objectives and data through accelerated data processing. DevOps, on the other hand, mainly focuses on product development. In short, here are some of the more detailed differences between DataOps and DevOps.
DataOps | DevOps |
Data operations | Development operations |
Use build, test, and release, and a few other steps in between | Uses just build, test, release |
Involves a mix of IT operations teams, and data management | Involves a mix of IT operations teams and product development |
Offers structured and accurate data | Offers faster deployment with least bugs and issues |
Fast delivery of data analytic solutions | Fast development and release of software products |
Automated data pipeline for companies | Companies are given a chance to release products faster |
Consistent coordination of ever-changing data | A fairly limited coordination |
What’s important are the data flows within the system | The software itself is important |
Evolution from ETL to DataOps Platform
For years, companies ingested data into on-premise relational databases using self-built data connectors. However, this process was too slow and expensive, and ETL tools gradually emerged for data ingestion.
But issues with database scalability, data transformation, and continued deficiencies with data connectors limited the strength of the insights.
Years later, cloud data warehouses eliminated hardware scalability issues, and ETL platforms began to close the gap in terms of data connectors. Ingesting data was no longer the problem; transformation was.
But soon, ELT platforms began to transform data inside the cloud data warehouse, leading to the rise in data lakes and unlimited insights from endlessly queryable data.
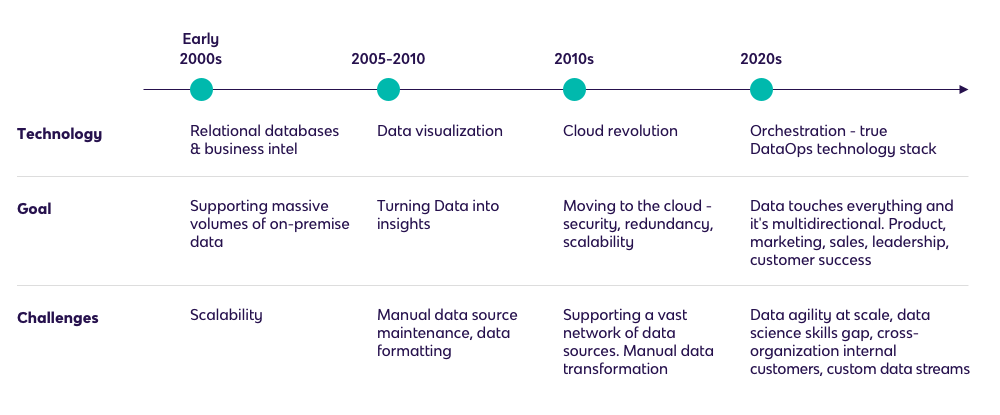
Today, the challenge facing data-driven companies is more about delivering data than generating it. Now, everyone in an organization needs data, and needs it in minutes, not in hours.
However, most traditional ETL platforms are still reinforcing an outdated framework that silos data and puts it only in the hands of a “chosen few.” That’s why DataOps platforms are built for this new era.
DataOps platforms do not just generate, but deliver, the right insights, at the right time, to the right stakeholder. With full data orchestration, DataOps platforms automate the democratization of data, from start to finish.
DataOps platforms eliminate the rigid, top-down data culture facilitated by traditional ETL platforms, for a bottom-up system that provides stakeholders in the trenches with the data they need.
FAQS
The idea behind the DataOps methodology is to enable an organization to build and expand data pipelines and analytics. Following data governance and the collaborative data management practice will enable the delivery of high-quality business data.
Ad-hoc analysis is a process during which data analysis is curated and created by users on demand or when needed. This produces highly customized reports which are created to answer highly specific questions. It was a popular technique back in the day, but the reports were only used for the intended purpose.
DataOps incorporates Agile Development practices to bring data suppliers and consumers closer to getting more accurate data.
DataOps processes record all ad-hoc workflows as code by continuously testing information. The information is validated and confirmed before it goes through the data pipelines and undergoes impact reviews. DataOps ensures the intellectual property is kept shared, reviewed, enhanced, and reused over again.
Data Science is the study of data like numbers, text, etc., and its goal is to gain knowledge and insight from this data. It’s a combination of tools, algorithms, and learning principles to find patterns from raw data.
DataOps enables efficient foreseeing of data and eliminates time-consuming data science algorithms by automating the process. It pushes flexibility and reusability to fit new use cases, and design-governed data allows the automatic implementation of policies in new pipelines.
The difference between DataOps and Data Engineering is their focus and scope within data management and analytics.
For instance, DataOps revolves around the operational aspects of data management. It streamlines the entire data lifecycle—from data ingestion to processing, analysis, and delivery. It does this by implementing agile methodologies, DevOps practices, and continuous integration/continuous deployment (CI/CD) pipelines.
However, Data Engineering focuses on the design and implementation of data pipelines and infrastructure. Data Engineers are responsible for creating robust data systems and designing data models; they work closely with data scientists, analysts, and other stakeholders to ensure the infrastructure meets data requirements.
In summary, although DataOps emphasizes the operations of managing data pipelines and workflows, Data Engineering focuses on the implementation of those pipelines and the underlying infrastructure.
