





















How to orchestrate dbt Core jobs in 3 steps

In the realm of data transformation, dbt stands out as an exceptionally popular tool among modern data teams.
dbt data transformation tool offers two versions:
- dbt Core: the open source version which is free to use, but requires setup and infrastructure maintenance to run it
- dbt Cloud™: the hosted version that offers Git-integrated code editing, job orchestration, APIs, and data quality controls on top of dbt Core’s transformation engine
And guess which version is best? The one that fits with your business needs. From a professional standpoint, many of our customers choose two methods to transform their data. They either let us fully-manage their end-to-end pipelines and complete their entire ingestion, transformation, orchestration and even Reverse ETL processes, or they opt to integrate with dbt for transformation.
When that happens, usually Rivery’s Logic Rivers, (rivers are our trademark name for pipelines) orchestrate a process where the data ingestion is executed by Source to Target Rivers. Once the ingestion steps are completed, dbt jobs are triggered to execute transformations.
To make this integration even more seamless, we created a kit to trigger dbt Cloud™ jobs through its API. A Rivery kit is a ready-made workflow template that literally takes your data flow from point A to Z in a few clicks. So the question you might be asking yourself is: what about dbt Core? How can Rivery integrate with dbt Core if dbt Core doesn’t offer a native API to trigger dbt jobs?
Confusing right? Ok, well that’s what this article is all about. It’s about making dbt Core jobs happen efficiently.
Rivery + dbt + GitHub Actions
I recently spoke with a client who is using dbt Core and they asked me how Rivery could help orchestrate their data workflows. They currently use GitHub to manage their code but still trigger the jobs manually. That’s so time-consuming and it’s just not scalable.
So, our GitHub Actions offer the perfect solution. GitHub Actions make it so easy to automate a workflow execution on any GitHub event. They’re a popular choice for running dbt Core jobs.
Let’s take a closer look at how you can do this with a real-life example. I’ve got a dbt-labs sandbox project, it’s called “The Jaffle Shop“. All I need to do is set up an MVP to use Rivery to ingest data, and then trigger a dbt Core job via GitHub Actions. It’s that simple.
3 steps to orchestrate dbt Core jobs
1. Set up the dbt project
First thing you need to do is fork the dbt project in our Rivery Github account: https://github.com/RiveryIO/dbt-demo-jaffle-shop
The Jaffle shop data is located directly in the repo, but in order to make the project a bit more realistic, I copy the CSV file data onto a Google sheet. I use Rivery’s Google Sheet integration to ingest my data. The data can also be saved to an SFTP, or a Cloud Bucket, workflow in the same way.
Then, I make a few configuration edits to ensure a smooth dbt job run:
- In the profiles.yml, I edited the Snowflake piece to connect with a username/password instead of an external browser: https://github.com/RiveryIO/dbt-demo-jaffle-shop/blob/main/profiles.yml#L11-L33
- I also changed the default schema name from “jaffle_shop_raw” to “dbt_demo_raw” (https://github.com/RiveryIO/dbt-demo-jaffle-shop/commit/0530b76ab292862cdaaba9b772831485de43a9c3)
2. Create a GitHub Action workflow
Once my dbt project was ready and working fine on my local environment, I moved on to use Github Actions to run the dbt job. I created this GitHub Action workflow: https://github.com/RiveryIO/dbt-demo-jaffle-shop/blob/main/.github/workflows/dbt_run_job.yml
The workflow is defined as follows:
- It can be triggered manually in GitHub (workflow_dispatch, L5) or via API call (repository_dispatch, L4)
- It will set the environment variables required by the dbt project: https://github.com/RiveryIO/dbt-demo-jaffle-shop/blob/main/.github/workflows/dbt_run_job.yml#L7-L16
- Then, in the GitHub Action Container, it will install Python and any required packages before running the commands “dbt run” and “dbt test”
I ran my workflow manually to confirm the setup was correct:
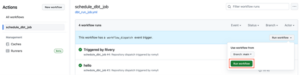
3. Automate an API call to trigger the Action
The last step was to use a REST API call to trigger this run. When a GitHub Action is defined to run on “repository_dispatch”, it means that we can make a POST request to the GitHub API to trigger the action.
An API call made to https://api.github.com/repos/{repos_owner}/{repo_name}/dispatches with the body {“event_type”: my_event_type} will trigger the Action to run. The event_type can be used to filter which specific Github Action should be run – quite useful for bigger projects that may be hosted in the same repository!
If you want to do so, change your workflow to define the “types” of incoming events that should trigger the action (L5 of the workflow.yaml):
on:
repository_dispatch:
types: [dbt_core_demo_rivery]
This API call in Rivery is easily configured via an Action River with the following inputs:
- API URL POST call: https://api.github.com/repos/RiveryIO/dbt-demo-jaffle-shop/dispatches
- A request body (populated via a variable that will be set later on under the Logic River):
{“event_type”: “{event_type}”}
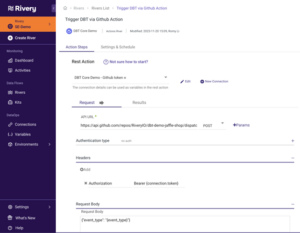
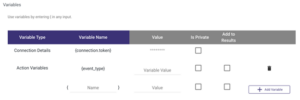
In addition, we also handle the authorization using a bearer connection token under our Action River variables:
The complete data workflow
It’s time to put it all together – we are now ready to build our complete data workflow using a Logic River:
First, ingest data from my data sources (i.e. Google Sheets) using Source to Target Rivers, then trigger my dbt job to transform my data in Snowflake using an Action River.
A couple of notes:
- The ingestion rivers are grouped within a Logic River Container. Using a Container allows us to ensure all the ingestion steps are occurring in parallel before the dbt transformation kicks off. In addition, it’s easier to read and modify the workflow by expanding and collapsing Containers.
- The Action River {event_type} variable is set to the specific event (“dbt_core_demo_rivery”) we want to run in this case.
To summarize, combining River’s ingestion and orchestration abilities with dbt can yield a tightly integrated process for sophisticated data pipelines. The outcome is low data latency for the business with zero time wasted between ingestion and advanced transformation.
Can't miss insights



Minimize the firefighting. Maximize ROI on pipelines.

