





















Open-Source vs. Managed Data Architectures: Which One Should You Choose?

Editors Note: This article was written alongside Hugo Lu CEO of Orchestra
In the data industry, it’s often easy to get caught up in the details and lose sight of the bigger picture: why are we even here in the first place? The answers to this fundamental question are as diverse and dynamic as the data sets we engage with daily.
In start-ups, a Lead Data Engineer might have been hired to deliver insights to the CEO on something as specific as product usage. By contrast, data teams within more traditional enterprise sectors might have been hired to help achieve a strategic vision; a broader goal of enabling data and AI for an entire organization.
The Raison D’etre provides some helpful context when considering what data architectures to reference. Is it best to buy or build tools in-house? What combination of tools is most scalable but is also quick to implement? Should I adopt a data warehouse or a lakehouse approach? These are all determined by why we’re here in the first place.
In this article, we’ll dive into two reference architectures for building an end-to-end analytics pipeline. The first makes use of open-source workflow orchestration tools, in-house-built ETL connectors, and Kubernetes. The second leverages Rivery, Orchestra, dbt-core, and Power-BI.
What are the advantages and disadvantages of leveraging open-source software?
The data industry benefits greatly from substantial investments in open-source software. Typically licensed under the MIT License, these software packages can be freely utilized by enterprises for their non-commercial purposes. Projects like Apache Airflow, dbt-core, and Airbyte exemplify this ethos, forming the bare bones of a “free” data stack.
That is not to say that leveraging such tooling doesn’t come with risks of their own:
- In the ZIRP era, It’s becoming increasingly common for companies to sunset support for their OSS product, change their licenses to other restrictive forms, and prevent specific use cases of software (thus pushing you to buy their enterprise solution.)
- There is no support other than community support for issues or bugs
- Crucially, running and maintaining OSS requires people and time investment, which can be significantly more expensive than the software itself
With this in mind, let’s set up a quick data stack with OSS software.
Building an open-source, low-cost data stack
In this example, imagine we’re Refreshing Drinks Inc. and we’re trying to understand sales trends in real-time so we can improve the demand planning process. To do this, we aggregate a set of customer information from our CRM and ingest sales data from a third-party API.
For the sake of ease, we’ll assume you’re using Snowflake as a storage and computing engine, but you could easily substitute this for Databricks, BigQuery, etc. We’ll also assume you’re working in Amazon Web Services (AWS), but again you could substitute this for Google Cloud or Azure.

Efficiently implementing Business Intelligence (“BI”)
Let’s work from the end product backward. In this case, our goal is to produce a dashboard shower sales by the customer over time. That’ll be done in Power BI.
A quirk of Power BI (common to Tableau extract refreshes and even Sigma with materializations) is that datasets need to be “refreshed” at the end of each pipeline This means that without co-ordinating this refresh, there could be missing data, stale data, or at worst: incorrect data that appears in Power BI.
To get around this, we need data orchestration.
Approaches to Data Orchestration
If upstream tasks fail then downstream tasks shouldn’t run, Imagine you ingest a file but there’s no data in it. How do you ensure your dashboard doesn’t simply have an empty day in it before you send that dashboard to your CEO? The answer is through data orchestration.
A popular open-source workflow orchestration tool is Apache Airflow. Apache Airflow needs to run on a Kubernetes cluster to perform reliably, as it is a heavy-weight solution comprised of a scheduler, a server, plugins, runners, and a database. This means you will require a DevOps or Platform Engineer to maintain this framework.
Data Ingestion (ETL, ELT, and everything in between)
To load the data into Snowflake from your CRM, you should leverage open-sourced, off-the-shelf connectors. To do this, you could run a package like pyairbyte or dlt to move data from source to target (in this case, Snowflake).
This would run on an EC2 machine, or perhaps be nested in an ECS Task depending on how “spiky” the workload was. You could also run the Airbyte Server yourself, managing the infrastructure and networking requirements as well as the deployment and version management.
Solving Data transformation with dbt (data build tool)
Once the data is loaded to Snowflake, there comes the task of joining the two datasets together. We have our customer list, and we have our sales data. Now it’s time to prepare that data.
A popular data transformation framework is data build tool or dbt (core). In answer to “What’s Data Build Tool?”, dbt is a developer framework for reliably and easily maintaining SQL commands that define data tables, views, and materializations.
In practice, many people run dbt-core on lightweight infrastructure such as an EC2 machine, ECS task, or even GitHub Actions. Although this makes democratizing the process quite hard, it’s cheap and reliable.
As we’ve already set up Airflow, we can also make use of running dbt-core there.
Summary
Tools used: Apache Airflow, dbt-core, Snowflake, Power BI, AWS infrastructure
Pros: minimal software cost, ability to run all code in one own infrastructure
Cons: significant maintenance cost, no support, building new pipelines requires highly technical knowledge
Building efficient data pipelines with best-in-breed tools
Part of the problem with adopting an approach that relies on community-maintained solutions is reliability and speed. OSS Frameworks and easy access to cloud infrastructure mean the right technical mind can build almost anything in the data space.
This doesn’t mean you should – which comes back to your raison d’etre. So far as speed and scalability are concerned, best-in-breed data tools represent a solid investment. Let’s see how.
Data Ingestion
Leveraging an open-sourced framework for data ingestion works great until it doesn’t. The first 5 data sources might go smoothly. But what happens when you have 20, 50 or a 100? What happens when something goes wrong?
One of the core features of Rivery is its managed connectors. Users can configure data movement from source to target using “ClickOps”. Not only is this scalable and quick, but it also democratizes the process and eliminates infrastructure costs.

Building out data connectors in Rivery is up to [90%] faster than building in-house. Rivery also provides an SLA, so if there are issues the data team doesn’t become a bottleneck.
Running dbt-core
Under the hood, dbt-core simply sends queries to your underlying data warehouse. Therefore, your underlying is doing the “heavy lifting”, and it makes no sense to simultaneously run a large Kubernetes cluster with a heavyweight framework like Airflow in parallel.
Many organizations run dbt-core on an EC2 machine or ECS Task to get around this. While minimizing infrastructure cost, it also offers flexibility and security by decoupling business logic (in dbt) from Orchestration logic (in Airflow). This is extremely advantageous to larger teams in enterprise environments, as it reduces management and security headaches.
You can also consider leveraging dbt-Cloud or Rivery’s in-built dbt capabilities for data transformation.
Orchestration
With the Rivery platform for ingestion, Snowflake, Power BI, and a small piece of lightweight infrastructure running dbt, you might be wondering if you still need to consider Airflow. The answer is “Probably not”.
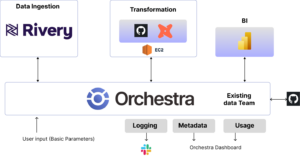
Orchestra is a lightweight orchestration platform built specifically for the Modern Data Stack. It offers a familiar and intuitive GUI for building pipelines, which means anyone can stitch together components of the data stack to build a data pipeline in a fraction of the time taken to merge a Pull Request into Airflow.

Furthermore, Orchestra runs on serverless compute which minimizes infrastructure costs. Under the hood, all pipelines are git-controlled so users get the benefit of an intuitive GUI but the comfort and reliability of git-powered version control.
The result of this combined stack is something incredibly easy to maintain, a highly scalable data operation, and one where the entire data team (technical and non-technical) can make use of Data and AI.
Minimizing Total Cost of Ownership
Why would anyone pay for software when a free version exists already? The answer lies in the Total Cost of Ownership.

Organizations with highly bespoke data requirements, low latency requirements, and/or big data requirements typically invest in data platform teams as custom infrastructure is required to facilitate their use cases.
Platforms like Rivery, Databricks, and Snowflake are already capable of crunching an enormous amount of data at high speeds. When decoupled from these processes, Orchestration and Monitoring have much lower and more homogenous/boilerplate infrastructure requirements.
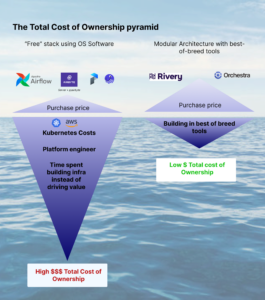
As software becomes more powerful, the proportion of companies requiring a platform team is decreasing. Despite this, the number of organizations seeking to minimize TCO or re-allocate platform engineering resources towards driving value from Data and AI is increasing – Rivery and Orchestra are accelerating this trend.
Summary
Tools used: Rivery, Orchestra, Snowflake, dbt-core/ECS, Power BI
Pros: TCO-optimized data stack, low maintenance, rapid set-up, high scalability, best practices enforced, SLA
Cons: software cost, multiple tools, complexity
Conclusion
In this article, we discussed two approaches to building a data stack. One using open-sourced components on its own to manage the infrastructure, and the other utilizes modern data stack tools like Rivery and Orchestra to build a TCO-optimised data operation.
We dived into the pros and cons of these approaches, and some considerations for using open-sourced software and self-managing infrastructure. We saw that what’s crucial here is our raison d’etre and the confines of our requirements.
For many organizations, hard and fast network security requirements may necessitate the use of components that can run within an organization’s own cloud. Other examples we touched upon were speed and latency – where sub-second latency is required, a different architecture might be required entirely.
By contrast, many enterprises seeking to reliably and accurately make use of Data for insights and analytics will likely best be served by a combination of Modern Data Stack tools.
We saw that leveraging Rivery together with Orchestra eliminates the need for organizations to invest in platform engineering, while simultaneously retaining flexibility, and scalability, and ensuring best practices like git-control and CI/CD.
The result is a scalable data operation where usage has an incredibly low barrier to entry. The icing on top is that this optimizes for cost as well as speed. This sets up organizations for success, not only in the realm of data but increasingly in Generative AI.



Minimize the firefighting. Maximize ROI on pipelines.

