





















Turn Your S3 Data Lake into an Analytics Engine in Half the Time

How to Easily Ingest & Prep Data for Amazon Athena
Turning your Amazon S3 data lake into a powerful analytics engine with Amazon Athena can be a fast and cheap way to unlock data insights. However, achieving this goal isn’t always a straightforward task for data teams. With data sources growing by the day and business requests for data following just as fast, data teams are under great pressure to stay one step ahead (or at least keep head above water).
This article covers how you can achieve this data professional dream using Amazon Athena combined with Rivery.
- What is Amazon Athena?
- ETL and Data Preparation for Amazon Athena with Rivery
- The Benefits of Using Rivery to Feed Amazon Athena
What is Amazon Athena?
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using SQL queries. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. In other words, Athena allows you to turn your Amazon S3 data lake into something that looks like an analytical database for any BI tool or app that can run SQL queries. The beauty is that it’s doing so, without having to deploy anything or move your data out of your data lake.
Under the hood, Athena is using Presto which Facebook started as a project to run interactive analytic queries against a 300PB data warehouse. The result was an open source, distributed SQL query engine, designed from the ground up for fast analytic queries against data of any size. Presto supports both non-relational and relational data sources including of course Amazon S3, where the data queried by Athena is stored.
Amazon Athena also includes native integration with Amazon Glue Data Catalog to expand its functionality. When you use Athena and Glue together, you can develop a unified metadata repository and open up other powerful capabilities.
You can put the Athena service to use with the following steps:
- Point Athena at the data you want to query in Amazon S3 (assuming you already loaded your data to S3).
- Define your database schema (commonly done in the Amazon Glue Data Catalog)
- Use standard SQL to query this data (i.e. from any BI tool).
Amazon Athena provides the easiest way to run interactive queries for data in S3 without the need to setup or manage any servers. The serverless infrastructure makes Athena excellent for businesses wanting to limit development resources to set up complex solutions. Finally, with the right optimization to your data structure definitions (i.e. applying partitions), you can keep costs relatively low when comparing to other cloud data warehouses.
ETL and Data Preparation for Amazon Athena with Rivery
To reap the benefits of having Athena turn your Amazon S3 into a digestible organizational data lake, you have to start by getting (all of) your data into S3 and as mentioned above, follow that by defining the schema for Athena. This is where Rivery comes into play.
With 200+ pre-built data connectors, Rivery allows you to instantly connect to key data sources and ingest the data into Amazon S3 in a few clicks. The pre-built connectors cover many SaaS apps, databases and even files but if you have a unique data source, you can also connect to it directly using a generic REST API connector. Those few clicks essentially create a managed data pipeline that will continuously bring data from your different sources.
But Rivery goes one step further to simplify your work with Athena. Instead of simply loading the data to S3, Rivery allows you to define the desired schema and database name within the Glue Data Catalog so data can be immediately queried by Athena. In that process, Rivery will automatically define your tables and columns directly in the Glue Data Catalog (which you can always tweak if needed as well).
To recap, this source to target data pipeline (river) will follow the next steps:
- Connect to your data source of choice.
- Extract the data from the source (could be either batch or CDC for database).
- Load the data into a landing zone within your Amazon S3 bucket.
- Use Athena CTAS to define your database schema, including columns and partitioning settings as well. Using CTAS will result in Athena storing data files created by the CTAS statement in a specified location in Amazon S3. The files will be stored using an optimized Parquet format for faster querying.
This data flow is illustrated in the following diagram:
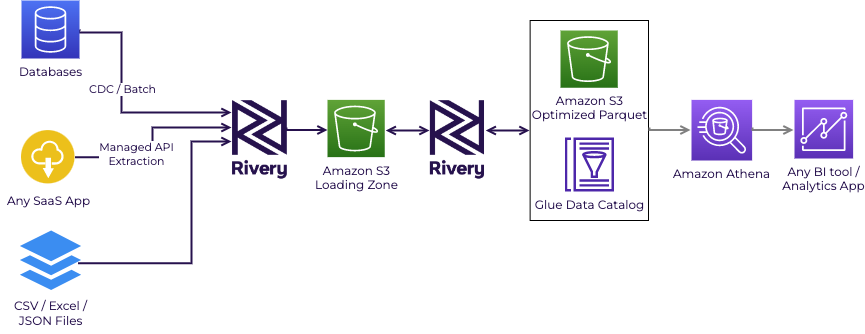
Rivery ELT flow for Amazon Athena
While behind the scenes, Rivery handles a lot of different steps, this data pipeline is actually very easy to set up. It could be as simple as choosing your data source (i.e. Shopify), Athena as your Target and scheduling your pipeline:

This data pipeline can also be orchestrated as the first step of a multi-step data pipeline that includes further data transformations as part of a full ELT pipeline. For example, with Rivery, you could extract and load data from an internal MySQL database and join it along with another dataset extracted from Shopify. All done using an efficient built-in incremental load and via triggered Athena SQL queries for additional transformations such as the said join.
The Benefits of Using Rivery to Feed Amazon Athena
Using Rivery to ingest and prep data for Amazon Athena is a game changer for data teams that look to move fast and eliminate unnecessary complexity when delivering data for their business. Here are the key reasons for that:
1. Bring all of your data into S3, ready for Athena using a few clicks
Rivery can write data to Amazon S3 and define it for Athena for more than 200 data sources so you can regularly pump data into your data lake from external data stores without having to worry about writing or managing API based integrations.
2. Zero overhead for your data pipelines infrastructure
Like Athena, Rivery is also a managed service. Companies using our technology don’t have to worry about installations, maintenance or scaling infrastructure to manage large data volumes.
3. Simplify your data ingestion and file management on your Data Lake
Rivery provides a simple UI based selection to choose between loading modes including handling Upsert – Merge. This solves for a challenging process when it comes to performing upserts on unstructured object storage such as Amazon S3 data lakes.
In addition, using a drop down, you can choose to partition data by date and time at different granularities. This custom partitioning yields better performance and cheaper queries while being effortless to set up.
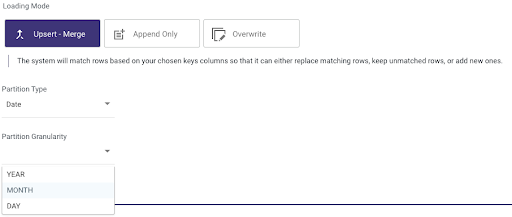
Choosing the default loading mode and partition type/granularity in Rivery
4. Transform your data to form the perfect data model
Once you ingest your data into S3, the next step is to model it. Rivery lets you orchestrate and run SQL queries or even Python scripts to shape your data exactly as needed. Rivery will then eliminate the need for you to define the Schema in Athena and will automatically reflect your new data structure in Glue Data Catalog, ready for downstream applications queries.
Let’s recap
Amazon Athena integration with Rivery helps Amazon S3 users extract, load and transform all their data sources to be query ready via Athena. With Rivery’s pre-built API connectors and modeling for Athena, this process is accelerated and simplified so data teams can focus on business logic rather than plumbing.
Ready to accelerate your S3 data lake usability – start for free here.
Want to learn more about what else Rivery can do for your data team? Talk to us.



Minimize the firefighting. Maximize ROI on pipelines.

