





















How to solve complex data pipeline challenges with managed Python

Part of the concerns of data engineers when moving from writing their own code to a modern data platform is around loss of control. We have seen that many times with those users trying a no-code platform and hitting a roadblock very quickly, helping them to “prove the point” that these no code only tools will not really speed or ease up their work. That is why we invest a lot in making sure Rivery is extremely flexible, yet provides that flexibility in as much as possible of an easy to use user experience.
Our managed Python capability is a great example of an extremely powerful option to help you accomplish almost any data integration related use case you cannot achieve with our no-code pipelines or SQL push-down transformations. With it, any data engineer can easily insert their own Python script, combine it with other SQL transformations and orchestrate a workflow to meet unique business requirements.
One such example is a recent challenge we got from one of our customers. They wanted to see if they could also automate a sentiment analysis data pipeline for their X (Twitter) data. The use case was designed to enrich their data warehouse with specific sentiments around their prospect brands so they use this data to tune their sales cycle.
The challenge was accepted and quickly turned around. Here are more details about this type of use case and how we solved it in Rivery:
X (Twitter) Sentiment Analysis refers to analyzing and classifying the sentiment or opinion expressed in tweets using Natural Language Processing (NLP) techniques. Sentiment analysis is a text analysis that helps businesses and individuals understand the emotions, attitudes, and opinions expressed in a large volume of social media data.
The process of X (Twitter) Sentiment Analysis typically involves three steps:
- Data Collection: The first step is to collect the tweets from Twitter using the Twitter API or web scraping techniques. Keywords, hashtags, user accounts, or other criteria can filter the collected data.
- Preprocessing: The second step is to preprocess the collected tweets by removing noise, such as stop words, URLs, punctuations, and special characters, and then tokenize the text into words or phrases. The preprocessing step also includes stemming or lemmatization to reduce the dimensionality of the text data.
- Classification: The third step is to classify the sentiment of the preprocessed tweets into positive, negative, or neutral categories using machine learning algorithms such as Naive Bayes, Support Vector Machines (SVM), Random Forest, or Neural Networks. The classification is based on features such as the presence of positive or negative words, emoticons, sarcasm, and context.
X (Twitter) Sentiment Analysis has numerous applications in business, politics, social sciences, and healthcare. For example, companies can use sentiment analysis to monitor customer feedback, track brand reputation, and detect potential crises.
If you aren’t familiar with Rivery – it is a fully hosted Cloud ELT platform which allows customers to connect to their data sources using a no-code approach for over 200 sources but also allows you to connect to any other data source using a low-code approach and then complete your data pipeline with transformation, orchestration and even reverse ETL.
For this sentiment analysis use case, we built a data pipeline to run a Python script to process the sentiment out of X’s data. Specifically, Rivery would support customers to host their Python execution pipelines which would complete the above steps in a Rivery Logic River with 2 steps:
- Complete all the X Data Collection, Preprocessing and Classification.
- Move the classified data to a Data Warehouse.
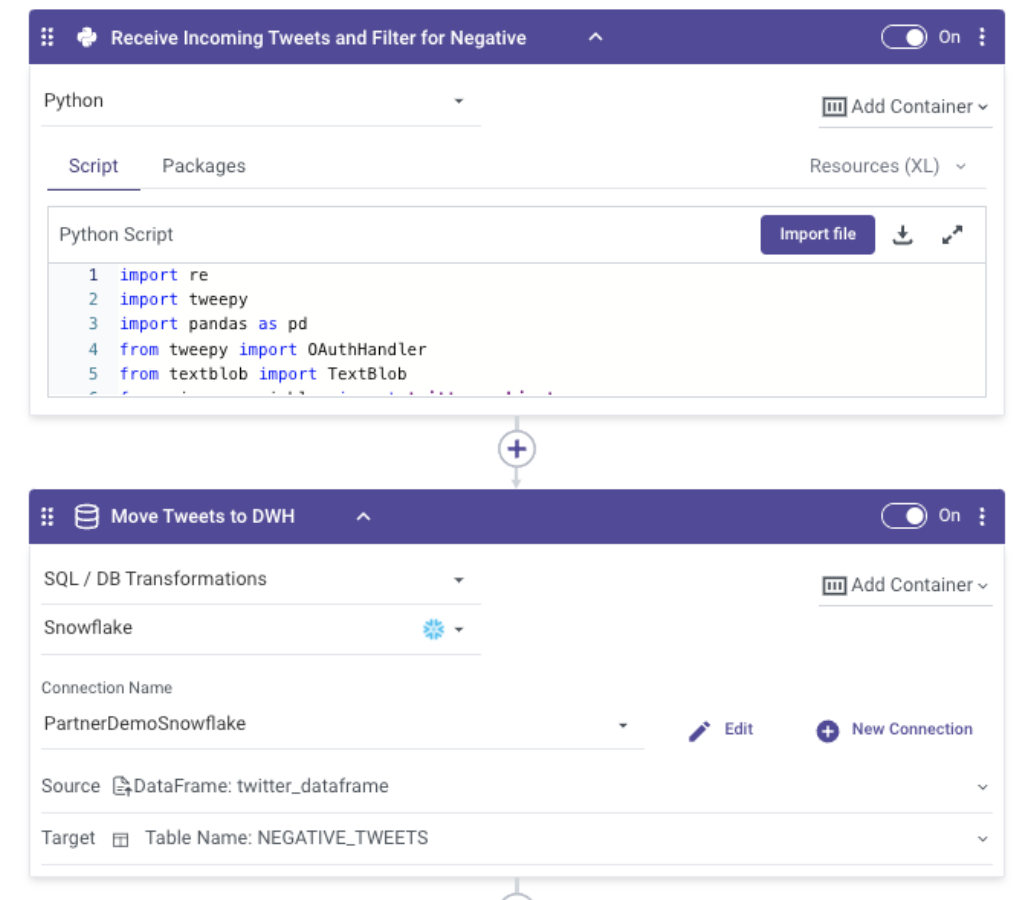
By using open-source python libraries like Textblob and a simple two-step Logic River – you can quickly analyze incoming data streams and move only the data you want to the warehouse.
For this requirement, Rivery supports customers to complete this advanced use case by providing an extensible but powerful fully hosted Python Execution environment with all the benefits of scheduling, notifications and the ability to orchestrate as part of a larger use case. We have seen Python being used to solve advanced use cases which are harder to solve with no-code or SQL alone such as:
- Advanced statistical calculations and basic forecasting
- Complex transformations on date and time
- Connecting and extracting data from unique third party sources
- Feature engineering for machine learning and ML scoring
Have another data integration challenge for us? We would love to hear more about your particular use case and put to test Rivery’s platform flexibility.
Can't miss insights



Minimize the firefighting. Maximize ROI on pipelines.

