





















What is Reverse ETL? Complete Guide

Reverse ETL is the process where data is transformed inside a data warehouse and then loaded into a third-party system for action-taking.
In today’s data-first economy, ETL is not just a process for centralizing data in a data warehouse. Increasingly, teams are using ETL to send data from a data warehouse into third party systems. “Reverse ETL,” as this method is known, is quickly becoming a core part of tech data stacks.
With Reverse ETL, data (insights and analytics) is fed back to the systems for further use in real-time. For instance, a company can use Reverse ETL to extract customer segmentation data from its designated analytics platform and then load it back into its CRM system.
By managing data like this, the company’s decision-makers and the sales team gain access to real-time customer insights. In addition, this allows them to customize their customer interactions and improve the effectiveness of their sales campaigns.
Here’s everything your data team needs to know about reverse ETL.
How Does Reverse ETL Work?
The mechanics behind Reverse ETL are more or less the same as those of standard ETL. One major difference is that Reverse ETL retrieves data from a data warehouse or an analytics platform and transforms it into a specific format adaptable to existing operational systems or other applications. Data is then loaded back into those systems. If it’s easier, you can think of Reverse ETL as a data-flow process in reverse.
First, a Reverse ETL process extracts relevant data from a data warehouse or a platform. The process might include product data, customer information, and other business-relevant insights. Next, the pulled (extracted) data is transformed to align with specific operational requirements within the target system. This step involves filtering, reformatting, or aggregating data.
Lastly, the transformed data is loaded back into designated operational systems or applications for further use. This specific process allows real-time access to reliable and valuable insights, enabling data teams and decision-makers to make educated decisions and employ actions based on the latest intel.
In essence, Reverse ETL is a process businesses use to modify the traditional data transfer process. Instead of extracting data from one source and loading it into a data warehouse, Reverse ETL relies on the same operational principles but in the opposite direction.
ETL vs. Reverse ETL – What is the Difference?
ETL (Extract, Transform, Load) focuses on moving data into the data warehouse for consolidation and enrichment. It transforms raw data into a standardized format and loads it into a central repository.
Reverse ETL does the opposite by taking this cleaned, enriched data out of the warehouse and transferring it into downstream tools like CRMs, marketing platforms, or other operational systems for team-wide use. This process ensures that the enriched data is accessible across various applications, enabling broader use within the organization.
To understand reverse ETL, consider this quick refresher on traditional ETL. Extract, transform, and load (ETL) is a data integration methodology that extracts raw data from sources, transforms the data on a secondary processing server, and then loads the data into a target database.
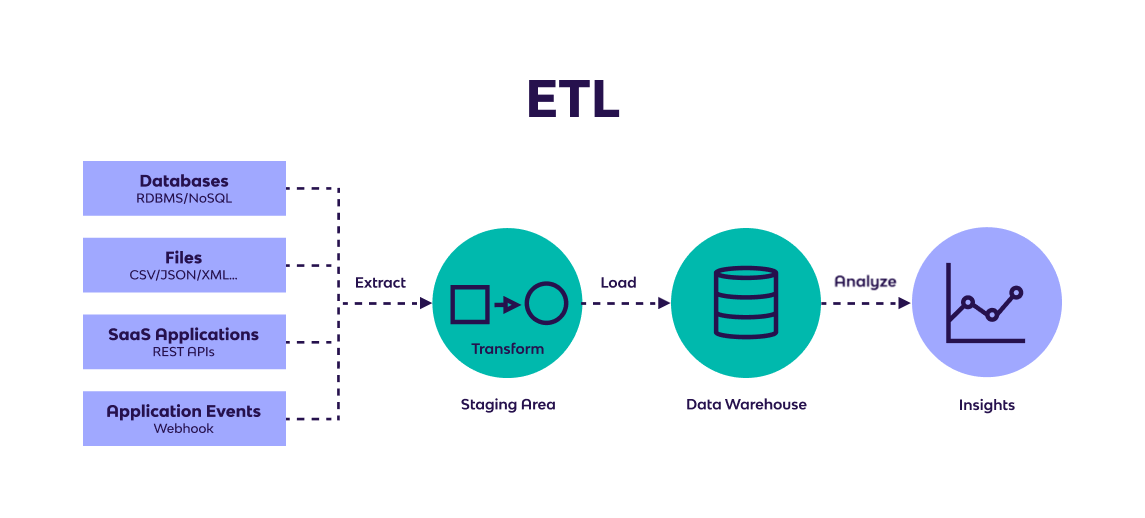
More recently, with the rise of cloud data warehouses, extract, load, transform (ELT) is beginning to supplant ETL. Unlike the ETL method, ELT does not require data transformation before the loading process. ELT loads raw data directly into a cloud data warehouse. Data transformations are executed inside the data warehouse via SQL pushdowns, Python scripts, and other code.
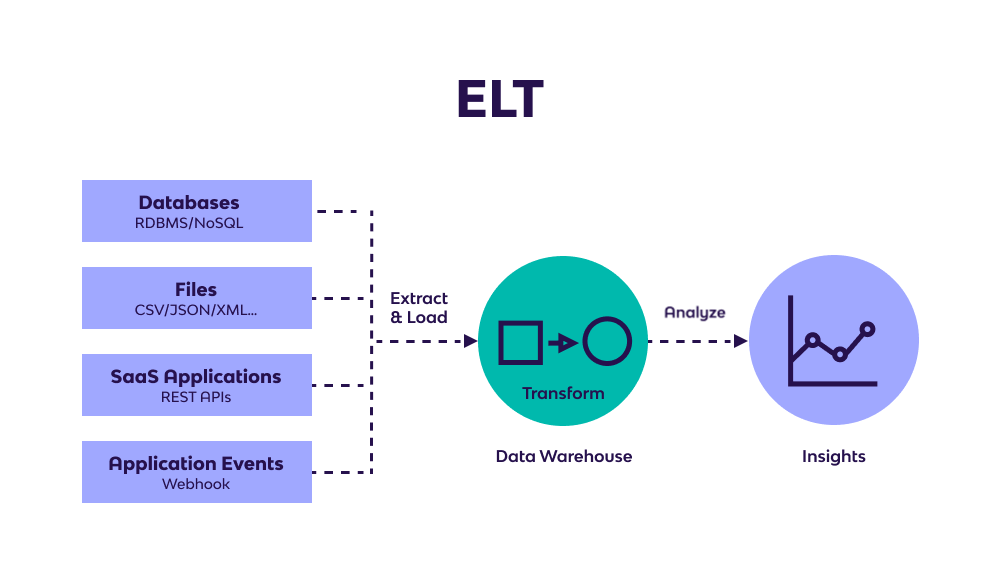
ETL and ELT both transfer data from third party systems, such as business applications (Hubspot, Salesforce) and databases (Oracle, MySQL), into target data warehouses. But with reverse ETL, the data warehouse is the source, rather than the target. The target is a third party system. In reverse ETL, data is extracted from the data warehouse, transformed inside the warehouse to meet the data formatting requirements of the third party system, and then loaded into the third party system for action taking.
Reverse ETL Process
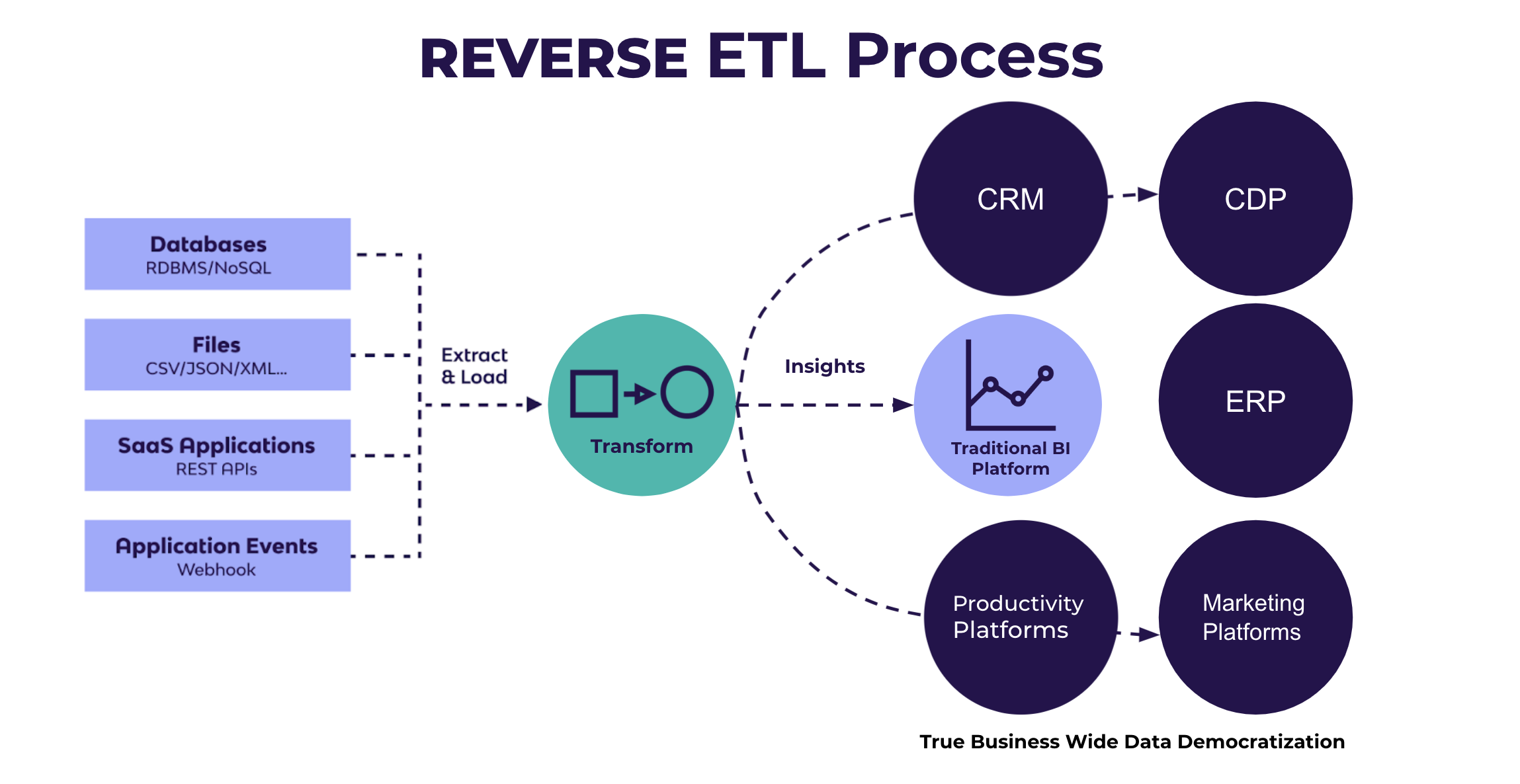
The method is referred to as reverse ETL, rather than reverse ELT, because data warehouses cannot load data directly into a third party system. The data must first be transformed to meet the formatting requirements of the third party system. However, this process is not traditional ETL, because data transformation is performed inside the data warehouse. There is no “in-between” processing server that transforms the data.
Here’s an example: If a Tableau report contains a customer lifetime value (LTV) score, this Tableau-formatted data is not processable in Salesforce. So a data engineer applies an SQL-based transformation to this report data within Snowflake to isolate the LTV score, format it for Salesforce, and push it into a Salesforce field so sales representatives can use the information.
Reverse ETL Use Cases
In today’s data-driven business landscape, Reverse ETL has found its practical use across several sectors. Some of the most notable use cases of Reverse ETL include the following:
- Real-time Sales Insights: Sales teams can use Reverse ETL to extract sales data from analytics platforms and load it back into their CRM systems. This particular integration allows sales reps to gain reliable, up-to-date information on customer behavior, purchase patterns, and sales performance straight from their CRM systems. Doing this makes it easier (and more reliable) to make data-driven decisions and identify cross-selling opportunities.
- Marketing Campaign Optimization: Marketing professionals can rely on Reverse ETL to elevate the effectiveness of their campaigns. By employing Reverse ETL, marketers are granted insight into the metrics of the performance of their marketing campaigns in real-time. Subsequently, marketers are empowered to make informed tweaks and modifications, optimize their targeting processes, and refine their marketing strategies.
- Personalized Customer Engagement: Businesses in the e-commerce sectors can tailor their customer recommendations in real-time. Reverse ETL allows data operators to extract customer browsing and purchase history from their data warehouse, transform it, and load it back into apps or websites. By doing this, businesses can offer their customers more personalized product/service recommendations, customized promotions, and more.
Why You Need Reverse ETL
There are several solid reasons businesses should use Reverse ETL, some of which refer directly to the business’s customer relations. Businesses of all scopes and sizes need Reverse ETL to bridge the gap between data and operational systems.
Businesses should use Reverse ETL to transform analytical insights into actionable data, make decisions in real-time, integrate their systems seamlessly, improve customer experiences, and boost overall operational efficacy.
Below are a few reasons why Reverse ETL is essential to businesses:
- Actionable data: With Reverse ETL, businesses can transform valuable data insights from data analytic platforms into actionable insights that operational systems can utilize. Loading relevant data back into the business’s operational systems allows teams to make better decisions and act in a timely manner. This, in turn, leads to improved efficacy.
- Decision-making in real-time: Businesses can rely on Reverse ETL to gain access to fresh, up-to-date data from analytic platforms that can be easily loaded into operational systems. This ensures teams have access to current insights and are knowledgeable to respond quickly to market changes, customer demands, and rising opportunities.
- Seamless data integration: Reverse ETL is the perfect solution for seamless data integration across different systems and apps in an organization. The process allows businesses to sync data across various platforms to ensure accuracy and coherence.
Where Does Reverse ETL Fit into Your Data Infrastructure
The Reverse ETL process plays a pivotal role in the data infrastructure by bridging the gap between central data repositories or data warehouses and operational apps and systems. A successful data infrastructure encompasses Reverse ETL as part of traditional ETL processes, assuming the role of a facilitator in the punching and transforming data from and to the operational systems within an organization.
This movement of data eases near-real-time or real-time updates and data integrations into different applications, allowing businesses to leverage their existing data more accurately and efficiently. In a well-rounded data infrastructure, Reverse ETL enables data teams to reach informed decisions and personalize and automate different data processes. In addition, Reverse ETL enhances the overall data environment by ensuring data flows both ways between storage and usage points.
Reverse ETL transforms and enriches data extracted from analytics platforms, making it more usable and suitable for different operational systems. It’s an integral segment in every wholesome data infrastructure, including data cleansing, data aggregation, reformatting, and/or applying specific business rules to align data with certain requirements of target systems.
Reverse ETL vs. Other Technologies
Reverse ETL differs from other processes by focusing on bidirectional data flow, enabling real-time decision-making, and integrating analytics into operational systems. Even though standard ETL, data integration platforms, data pipelines, and data replication technologies fall within a similar category, they cater to different purposes.
Traditional ETL technologies are designed to extract data from different data sources, transform it, and load it into a platform warehouse for further use and analysis. Comparatively, Reverse ETL takes data from the analytics platforms and loads it back into operational systems. ETL allows for data analysis and reporting, while Reverse ETL integrates insights into operational workflows.
Data integration platforms like Apache Nifi allow data movement and synchronization between data systems but are more dedicated to streaming data between applications and systems. Reverse ETL focuses on the bidirectional data flow between analytics platforms and operational systems.
Data replication technologies, such as CDC mechanisms, are developed to keep data copies synchronized across various data systems. Data replication can render data consistency, but it is typically used for cases involving disaster recovery and distributed database architectures.
What’s the Impact of Reverse ETL?
By pushing data back into third party systems such as business applications, reverse ETL operationalizes data throughout an organization. Reverse ETL enables any team, from sales, to marketing, to product, to access the data they need, within the systems they use. The applications of reverse ETL are numerous, but some examples include:
- Syncing internal support channels with Zendesk to prioritize customer service
- Pushing customer data to Salesforce to enhance the sales process
- Combining support, sales, and product data in Hubspot to personalize marketing campaigns for customers.
Even in companies with a cloud data warehouse, data does not always end up in the right hands. Reverse ETL solves this problem by pushing data directly into the applications leveraged by line-of-business (LOB) users. In some companies, teams already have access to the data they need via BI reports. But, to the dismay of BI developers, these reports are often underutilized.
What teams really want is to access data within the systems and processes that they are familiar with. This is exactly what reverse ETL enables. With reverse ETL, business users can actually harness data in an operational capacity. Teams can act on the data in real-time, and use it to make key decisions.
Reverse ETL can also streamline data automation throughout a company. Reverse ETL helps eliminate manual data processes, such as CSV pulls and imports, involved in data tasks. Sometimes, reverse ETL is another way to complete a step in a broader data workflow. For instance, if you’re building an AI/ML workflow on top of your Databricks stack, reverse ETL can push formatted data into the sequence. Companies are also increasingly incorporating reverse ETL into in-app processes, such as syncing production databases.

Reverse ETL: What’s the Right Solution?
A team can either build or buy an ETL solution. Those that build an ETL solution must create data connectors — the connection between the data source and the data warehouse — from scratch. This building process can take weeks or months, depending on the development team, and hampers scalability, drains dev resources, and saddles the system with long-term maintenance requirements. For these reasons and others, data teams often consider SaaS ETL platforms.
SaaS ETL platforms come with “pre-built” data connectors. The number of connectors vary by provider, but platforms often offer “plug-and-play” ETL connectors for the most popular data sources. However, these data connectors extract data from third party systems and load them into data warehouses. Reverse ETL data connectors are the opposite. They must extract data from data warehouses and load them into third party systems.
In other words: an ETL data connector is not a reverse ETL data connector. So when you see ETL platforms advertising ETL data connectors, that does not necessarily mean that a reverse ETL data connector is also available. In fact, it’s not uncommon for teams to adopt an ETL platform and still have to build reverse ETL connectors on the backend.
Building a reverse ETL connector can be just as intensive as building a traditional ETL connector. So, if reverse ETL is important to you, research the feature for each platform before you buy. At Rivery, we offer reverse ETL for all of our data sources, including via Action Rivers. Send data from your cloud data warehouse to business applications, marketing clouds, CPDs, REST APIs, and more.
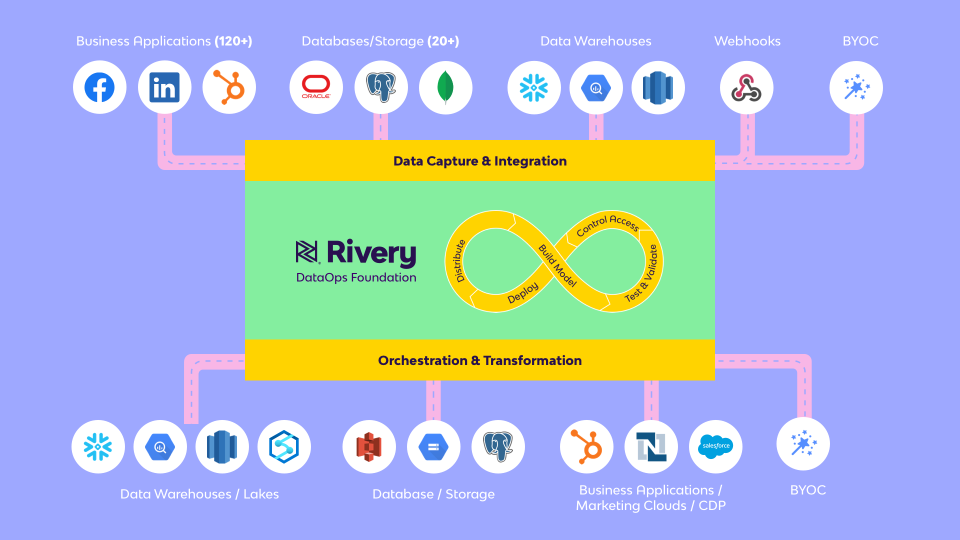
Simple Solutions for Complex Data Pipelines
Rivery's SaaS ELT platform provides a unified solution for data pipelines, workflow orchestration, and data operations. Some of Rivery's features and capabilities:- Completely Automated SaaS Platform: Get setup and start connecting data in the Rivery platform in just a few minutes with little to no maintenance required.
- 200+ Native Connectors: Instantly connect to applications, databases, file storage options, and data warehouses with our fully-managed and always up-to-date connectors, including BigQuery, Redshift, Shopify, Snowflake, Amazon S3, Firebolt, Databricks, Salesforce, MySQL, PostgreSQL, and Rest API to name just a few.
- Python Support: Have a data source that requires custom code? With Rivery’s native Python support, you can pull data from any system, no matter how complex the need.
- 1-Click Data Apps: With Rivery Kits, deploy complete, production-level workflow templates in minutes with data models, pipelines, transformations, table schemas, and orchestration logic already defined for you based on best practices.
- Data Development Lifecycle Support: Separate walled-off environments for each stage of your development, from dev and staging to production, making it easier to move fast without breaking things. Get version control, API, & CLI included.
- Solution-Led Support: Consistently rated the best support by G2, receive engineering-led assistance from Rivery to facilitate all your data needs.
Reverse ETL: Put Data to Work, Make Results Happen
Data warehouses were introduced to eliminate data silos. But for too many companies, data warehouses have become data silos. Reverse ETL solves this conundrum by removing the barrier between a data warehouse and the rest of the company. Now teams can operationalize data, in the systems and processes they feel comfortable with, and act on data to drive results. In today’s breakneck data economy, reverse ETL puts data in the hands and workflows that need it, when they need it.

Can't miss insights



Minimize the firefighting. Maximize ROI on pipelines.

