





















5 Data Integration Projects You Can Automate Right Now
Data Integration Projects
Inefficient Processes? Automate Them Away!
Many teams still perform data integration projects using inefficient processes and manual grunt work. And in today’s market environment, where maximization of value can determine success or failure, the teams that
eliminate these bottlenecks are well positioned to thrive even in challenging times.
Data teams encounter inefficiencies everywhere. Configuring each individual database table for a cloud migration. Managing the data orchestration process. Rebuilding data pipelines from scratch. But let’s face it: teams have better things to do than busy work.
Most teams are well-aware of the benefits of automation. But oftentimes, they either can’t find a platform with the right automation capabilities, or they subscribe to the “if it ain’t broke, don’t fix it” mentality.
With each passing day, the “can’t find a solution” objection is becoming less common. New solutions are now automating many of the data processes that make projects less efficient.
The “if it ain’t broke, don’t fix it” objection is a bit trickier. Most teams have an incentive to keep solutions that are “good enough” in place. These solutions work to an extent, and a transition to something unfamiliar always brings about a fear of the unknown.
But in today’s data landscape, “good enough” isn’t good enough.
Up to 80 percent of the effort involved in data warehousing is spent on data integration processes. Technology and competition threaten to leave behind teams that are not trying to automate these tasks. And this directly impacts the bottom line as well. Companies lose 20 to 30% of revenue every year due to inefficient processes. Never mind all the hair that team members pull out.
The truth is, there’s never been a better time to automate data processes. Now is the perfect moment to seize the opportunity.
Here are five data integration projects you can automate right now.
1. API Integration
Many teams rely on a wide variety of data sources, whether that’s Facebook, Salesforce, NetSuite or countless others. To provide holistic business insights, these data sources must be aggregated into a single repository, such as a cloud data warehouse.
However, in order to perform aggregation, the data warehouse must provide a data connector for each individual data source. There is no “one-size-fits-all” data connector. Each data connector is designed to match a specific API.
This gives teams two options for API integration: building data connectors, or leveraging pre-built data connectors. Each option offers its own pros and cons.
BUILDING API CONNECTORS
PROs
- Connector is 100% owned by company
- Team can get underneath the hood
CONs
- Requires developer resources to create
- Longer time-to-launch for data sources
- No automatic updates
- Lack of support channels
- Employee headcount may increase
The benefits of building data connectors mostly revolve around the company owning the entirety of the code. This makes it easier to customize a connector. But the method comes with downsides.
Developer resources, already scarce in most companies, are required to build API data connectors. The connectors take a significant amount of time to develop, and they do not automatically update for new API versions. There are no support channels to answer questions or concerns. And headcount in departments, such as data engineering, may increase to support data connector projects.
PROs
- Plug-and-play functionality
- Immediate time-to-launch
- Latest API updates incorporated
- No developers required
- Active support channels
CONs
- Unmodifiable without permission
- Solution owned by another company
Pre-built data connectors, on the other hand, eliminate the building phase altogether. With plug-and-play functionality, pre-built data connectors automate the API integration process. Pre-built API connectors link to data sources immediately. The dev team can focus on more important projects, and no new hires are necessary. All API updates are automatic. Support channels are available.
Pre-built data connectors are usually licensed by data integration platforms. Some platforms charge per connector, while others only charge for the data used. Pre-built connectors offer significant advantages to teams that need to automate API integration. But teams who need total control over the connector’s source code should consider self-building.
2. Data Framework Optimizations
A data framework refers to the infrastructure and processes that interact with data as it travels through a workflow. This can include not only code, but also physical components such as servers. Data framework optimizations can lead to improved performance and cost savings
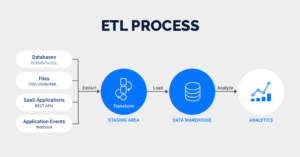
With ELT and Logic Rivers, teams can automate data framework optimizations. But first, a quick refresher. For decades, data integration solutions were modeled on ETL (extract, transform, load). ETL is designed to:
- Extract raw data from data sources
- Transform the data on a secondary server to meet the target database’s requirements
- Load the transformed data into the target database
But in the past few years, ELT (extract, load, transform) solutions have emerged as a key alternative. ELT was built to:
- Extract raw data from data sources
- Load raw data directly into a target data warehouse
- Transform raw data inside the target data warehouse itself
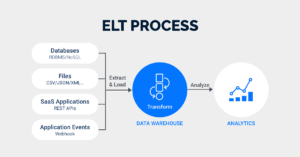
By removing the need for a secondary server, ELT inherently optimized many data frameworks. With ELT, data transformation is performed inside a cloud data warehouse, leading to faster, cheaper, and more efficient framework flows. But now that the technology is more widespread, teams that want a competitive edge should consider building on ELT’s optimizations using automation.
That’s where Logic Rivers come in.
A Logic River automatically orchestrates and transforms an entire data workflow, from start to finish. Logic Rivers allow teams to automate both the ingestion of data into the cloud and in-database transformations in the same workflow. With Logic Rivers, teams can automate core data framework optimizations. A perfect example of this appeared in our recent Case Study of AB Inbev:
“AB Inbev’s data stack initially included Hadoop, Azure Data Factory, Azure Database, and Azure Synapse Analytics. To eliminate Hadoop, Azure Database, and Azure Data Factory, the team automated both the ingestion of data (orchestration) and the execution of SQL queries (transformation) inside Azure Synapse Analytics using a Logic River. AB Inbev eliminated three of four solutions by automating this data framework optimization.”
3. Cloud Data Migration
With cloud data migrations, teams must migrate enormous amounts of on-premise data into a cloud data warehouse. For such a sprawling project, there are often many time-consuming and resource-draining tasks.
These tasks include mapping and source management, creating a data pipeline for each table, and tracking changes across all data sources, among many others. However, there are a number of ways to eliminate inefficiencies by using automation, such as:
Choosing ELT over ETL
While ETL requires data to pass through a secondary server, ELT automates loading raw data directly into a cloud data warehouse. By bypassing the secondary server, ELT speeds up the data migration process significantly.
Eliminating technical grunt work
Teams can automate a significant amount of technical grunt work by adopting a fully managed, no-code, auto-scalable data integration platform, along with pre- built data connectors and data process automation.
Confirming data quality
Data quality solutions offer data verification between source and target. These solutions automate integrity checks throughout the migration process, alerts for data discrepancies, and validation across all data.
Maintaining data continuity
A continuous migration automates data congruence between your cloud data warehouse and your database. This enables you to manipulate and analyze up- to-date data in the cloud.
Also, while many cloud migration solutions emphasize automation, sometimes these capabilities are more spin than reality. Consult objective review sites with real experts to make a decision, such as TrustRadius, G2, Capterra, SoftwareReviews, and PeerSpot.
4. Duplication
Particular data integration projects or processes sometimes demand duplication. Whether starting afresh, cloning a particular environment, or supplementing an already existing effort, the task of duplication is not necessarily a trivial one. This could entail remaking every single data pipeline, logic flow, database linkage, or any other part of a previous project.
Manual duplication can become extremely time-consuming, depending on how much a team plans to copy. Manual methods also risk miscopying from human error. This can result in faulty data and disrupt proper analysis. But by using a data integration platform that automates duplication, teams can avoid these headaches altogether.
Examples of scenarios that might benefit from automatic duplication include:
- A marketing agency duplicating a pipeline collection for each new client
- An e-commerce business duplicating its entire SQL engine for another project
- A video game company duplicating a 2019 social media campaign for 2020
- A sporting event sponsor duplicating separate, identical projects foreach game
- A wastewater group duplicating data pipelines for each separate facility
Automated duplication might not sound like a huge deal. But sometimes it’s the difference between a 10 hour project or a 20 hour project.
5. Data Syncs
Oftentimes, a company’s on-premise database collects data such as items sold, daily revenue, and other localized metrics, while the cloud data warehouse combines data from all the company’s internal and external sources. To stay aligned with each other, the on-premise and cloud databases must perform some kind of data sync.
Data syncs ensure that databases are congruent, enabling up-to-date datasets and more incisive business intelligence. While data sync methods such as scheduling remain popular, change data capture (CDC) is the only solution that automates the entire process.
Before change data capture, database migrations relied on bulk reading and batch processing. Data syncs were not automated or instantaneous. Teams were bogged down in manual source configuration. These factors made data integration more difficult.
Change data capture eliminated all of that. CDC automatically and instantly syncs a database with a cloud data warehouse by using real-time streaming. The syncing method detects data changes as they happen, and immediately pushes these changes into the target data warehouse.
CDC COMPARED TO OTHER DATA SYNC METHODS
Feature | CDC | SCHEDULER | MANUAL |
Premise-to-cloud | ✓ | ✓ | ✓ |
Automated | ✓ | ✓ | |
Only overwrites changed data | ✓ | ✓ | |
Real-time syncs | ✓ | ||
No additional SQL load | ✓ | ||
Handle deleted records in target system | ✓ |
With CDC, data is always identical. The source database and cloud data warehouse are continuously synced. No database resources are ever wasted. Database logs are scanned to track changes, adding no additional SQL loads to the system. Bulk selecting is a thing of the past. Only the modified data is synced with the cloud DWH. All other data remains static.
For a variety of data projects, CDC’s automation is a game-changer. The feature is especially useful for backing up operational databases in a cloud data warehouse, high frequency database syncs, combining marketing and internal data within a data warehouse, or any project that requires auto-syncs.
Take Efficiency to the Next Level
Automate Data Integration Projects Today
In today’s challenging market environment, teams need to maximize value across all projects in order to flourish. As more companies turn to automation to realize new efficiencies, data-driven teams must not become enamored with solutions that are just “good enough.” If companies wait to act on automation, they will remain exponentially behind the curve, or perhaps even barely treading water.
Of course, no one is expecting any team to automate all projects overnight. There is something to be said for the stability of reliable solutions, and throwing everything out all at once would likely do more harm than good. But automation is a force that no team can afford to ignore. The scenarios in this guide are just a few examples of how to make smart, targeted efforts at automating data integration projects right here, right now.
So what are you waiting for? Get automating!
