





















The Advantages of the Modern Data Platform over the Modern Data Stack
The more things change, the more they are the same.
Even with the progress made in data tools and the transition to cloud-native setups, the primary objective of data teams remains unchanged: enabling analytical tasks. Nevertheless, data teams face ongoing challenges to expedite results delivery using limited resources, all while maintaining a focus on maximizing return on investment (ROI).
In reality, the sophistication of your data stack or the inclusion of the latest trendy tools in the community doesn’t matter. Nowadays, with the rise of cloud-native technologies, data tooling is primarily focused on extracting data from sources, loading it into a data warehouse or lake, transforming it, and serving it to internal and external stakeholders.
It’s not just us thinking about this as well. It’s also at the top of the minds of other prominent names in the data industry.
Although traditional on-prem data stacks have been around since the 1990s, they had their limitations, leading to the rise of cloud-native technologies and subsequently the modern data stack.
Coined by the data community, the modern data stack (MDS) refers to a collection of mostly cloud-native tools centered around a cloud data warehouse. These tools form a data infrastructure architecture that organizations leverage to deliver data faster to become data-driven. However, it seems that the popular buzzword “modern data stack” has run its course, prompting the question, what’s next for the modern data stack?

When the modern data stack picked up momentum in late 2016, early 2017 products that took advantage of the cloud differentiated themselves from other pre-existing products that failed to quickly adapt to meet market demand.
Companies were leveraging the power of cloud-native technologies and the growth of data workloads in the cloud largely accelerated due to the maturation of products like Redshift, Snowflake, and BigQuery for computing.
Over the past six to seven years, these products have risen in popularity and helped share the MDS into what it is today. And, while the modern data stack was all the hype in 2021 and 2022, data teams are starting to see its shortcomings take center stage. Throughout this e-book, we’ll dive into the evolution of the modern data stack, its gaps in achieving value at scale, and what advantages a modern data platform provides over the modern data stack.
Pre-modern data stack
It’s astonishing to reflect on this in 2024, considering every company now claims to be “data-driven.” However, before the ascent of cloud-native technologies, a significant challenge faced by data teams was their inability to analyze data rapidly enough to meet the growing demand.
For starters, this process was incredibly time-consuming and even working on a pretty straightforward analysis was resource-intensive, time-consuming, and expensive to perform.
Before the rise of ELT, data was transformed before loading it into the data warehouse (ETL), and BI tools were mainly used by centralized data teams since engineers were worried that too many user requests could overwhelm the data warehouse.
Yes, you could imagine the nightmare scenario data teams felt from fielding ad-hoc data requests one after the other without a self-service way in place. All these data requests were a great sign that companies were starting to realize the value of data, but, for data to be valuable it had to be readily accessible to stakeholders.
The rise of the modern data stack
Looking back at this now, it felt like overnight, most of these problems disappeared for organizations, with cloud technologies gaining popularity. First, it was AWS Redshift that rose to the scene, making data analysis faster and cheaper for organizations. Then, it was Snowflake, which separated storage and compute, could auto-scale up and down, and only charge you for what you’re using (pay-per-use model), which was a nuanced approach at the time.
Now, tools that were meant to handle ETL workloads have become legacy software. New vendors appeared overnight and built a set of tools better suited for cloud-native environments.
Yes, the modern data stack did bring a lot of benefits to the data community and has helped shape data into what it is today. After all, these technologies were:
- Easy to use with some tools being low code, no code, or a code-first approach. Now, you don’t need to have an in-depth knowledge of coding to use some of these tools (yes, you should know some basics), but it is much easier to work with data than it was previously.
- Lowered the barrier to entry in terms of upfront and maintenance costs. The days of paying for on-prem servers were left in the past and consumption-based models allowed users to only pay for what they used.
- Tend to speak the same language by leveraging SQL push-down transformations in data warehouses (hello ELT). Is data engineering constantly changing? Absolutely. Is SQL going away soon? No. Even the top tier-low code or no code tools are built around SQL.
But now, we have reached a tipping point with the modern data stack. The sheer number of specialized tools that make up the stack, catering to every use case from ingestion and transformation to data warehousing, visualization, observability, and DataOps is overwhelming. The reality is, that most data teams today grapple with the complexity of navigating as many as 10 separate data tools every week. It has gotten to the point where the modern data stack if not managed right can be counter-productive.
The original idea of the modern data stack was to increase the time to value for data teams to deliver data insights. But now, the overwhelming amount of tools (as shown below) is making it increasingly challenging for data teams to deliver value quickly and cost-effectively.

By no means are we saying the modern data stack is a bad approach. It was just another phase of technology that everyone quickly brought into the hype. Like most things that get adopted very quickly, soon after you start realizing there are some shortcomings and something better comes along.
The downfall of the modern data stack
What’s great about the data market today is that companies are realizing that data is a first-class citizen. And while that is exciting, it also puts more stress and pressure on data teams to deliver high-quality data to serve multiple use cases.
As we mentioned earlier, the modern data stack is filled with tools that all have to integrate with one another. The proliferation of tools disperses and silos data across platforms, leading to blind spots in crucial data management areas like data quality, version control, and costs.

Fragmented ownership of tools across teams directly impacts business operations, especially in informed decision-making and product development.
Specifically, we have seen three main shortcomings when working with the modern data stack.
1. Integration hell:
A typical MDS implementation requires between four to five tools for ingestion, transformation, orchestration, and activation. And that’s just the fundamental data production portion of all your data operations. A complete MDS implementation also includes a data warehouse tool, a BI tool, an observability tool, and maybe even a data cataloging tool.

2. Bottleneck prone:
Modern data stack technologies are linked together in a linear chain. Naturally, there are pressure points in terms of integration and manpower. A lot of resources are required to serve insights to the entire business. Tech-wise, upstream processes enable downstream processes. So if one link in the chain fails nothing downstream can function or get updated properly. It demands a lot of workarounds.

In terms of manpower, if you only have one team to centrally manage the entire stack it can become a serious problem. Since each tool is different (some offering a no-code experience while others a command line approach), it’s natural for those teams to split the knowledge and have different engineers specialize in different tools. If something goes wrong and there’s only one or two team members to turn to for help and gather knowledge, it leads to serious inefficiencies. Business value can’t be delivered fast enough because the knowledge of the tools isn’t widely available to all.
3. Time to ROI lengthens:
ROI means ramping up to handle a faster influx of data workloads without having to double your headcount or infrastructure. Nowadays, businesses are catching on to the immense value of data—it’s a solution to a wide range of problems across different teams. But here’s the catch: this realization poses a big challenge in terms of business economics. Data teams have to be ready for the classic Three Vs of data: volume, velocity, and variety of the data itself. But now a variety of use cases may call for some overlapping architecture and completely different architecture in some cases. With a tech-first mindset, this is a scary thing cost-wise, due to the bottlenecking and mini-ecosystems of metadata. In turn, this largely affects the bottom line of a data team, which is their time to deliver value, or their time to ROI.

As time ticks on, we keep adding more data sources and beefing up our data models, all in the hopes of boosting business value. But with each evolution of our data models and every tweak to the schema, keeping tabs on our data sources becomes trickier, pushing us into a new phase of scalability.
Suddenly, we’re not just serving the original team we built our first use case for. Each team comes with its own unique needs—whether it’s diving into machine learning, artificial intelligence, or activating data. When everything is locked away in one team or domain, sharing data and getting access to it becomes a headache, making it tough to meet specific needs quickly and at scale. No data team wants to become a glorified service desk.
As we scale, the stack of different use cases grows, and soon enough, the data team is swamped with requests. That spells bad news for operational efficiency. Data gets scattered more products in our stack, leaving engineers in the dark about what’s happening in the pipeline. To cope with demand, data teams turned to hiring additional engineers but with resources being the most expensive line item on the data team expense sheet, the positive ROI from data initiatives is no longer there.
All of this slowed down the ability of data teams to treat data like first-class citizens. Data teams need to address these challenges head-on and the need for an innovative data management solution has never been clearer.
Enter the Modern Data Platform
With all the modern data stack’s shortcomings, there is a better path forward for data teams. Figuring out the ideal setup isn’t a straightforward task—it ultimately hinges on your unique business objectives and requirements. One thing is certain: change is necessary. Simply stringing together tools in a linear fashion to deliver data sets or products to the business, as we’ve been doing, just doesn’t cut it anymore. The more data tools you introduce across your organization, the higher the risk of accumulating technical debt, which only complicates matters further.
What’s becoming increasingly evident is that adopting a unified approach to the data ecosystem streamlines the various components that plug into it. This unified method should offer a set of building blocks that can be assembled in any necessary order to create more comprehensive and precise solutions, featuring components that are both loosely connected and tightly integrated.
Enter the modern data platform—a unified solution that consolidates the stack to function harmoniously in a shared language, all managed from a central hub. It brings together your data, ensuring seamless connectivity and performance optimization from ingestion to orchestration. Moreover, its adaptability allows for integrating existing tools in your stack, empowering you to effortlessly harness tools like dbt for data transformation and tailor aspects of the platform to suit specific business requirements. Essentially, the modern data platform embodies the core principles of the modern data stack while offering unified control over your data pipelines from start to finish.

Core attributes of the modern data platform
- Zero infrastructure to manage
- Infinite scale
- No-code data ingestion for any data source
- Managed SQL and Python modeling
- DataOps and API-first
- Proactive troubleshooting
- Holistic management of end-to-end pipelines
- Predictable value-based pricing

Advantages of the Modern Data Platform
Sure, a modern data platform sounds fantastic, but what tangible business value will your team derive from it over a Modern Data Stack?
1. Faster time to value
With fewer tools to set up and manage, the modern data platform instantly eradicates the friction in data delivery and dependencies. Each component of the modern data platform speaks the same language end-to-end, dramatically reducing the painful context switching between no-code and code-first tools.
2. Skill shift in dev and maintenance
The modern data platform’s end-to-end architecture helps to cut down the intensive coding effort and dev work involved in data pipeline creation and maintenance. When everything is unified end-to-end, you can templatize and reuse pipelines to automate workflows across the entire pipeline. So an entire use case becomes easy to deploy and replicate, saving pivotal engineering time and simplifying day-to-day operations. Not only does a platform approach substantially reduce the coding effort to create end-to-end data pipelines, but it also simplifies the day-to-day operations and development tasks due to the pipeline’s transparent architecture.
As one data team shared with us, “Everybody on the team is now comfortable with doing the vast majority of transforms we need.” Another IT organization said “The simplicity of the platform has enabled staff to explore more modern alternatives to its currently deployed data warehouses. We couldn’t hire fast enough to cover our growth. Now, one engineer can do the work that used to take five people.”
3. Increase in engineering efficiency
By consolidating the functionality into a single interface, the modern data platform accelerates the deployment of new pipelines and the ability to identify and diagnose issues in existing pipelines. Rather than switching between tools to understand the full context of a pipeline, engineers get a clear line of sight into their pipeline, with the ability to track changes, implement continuous integration and continuous deployment (CI/CD), and code versioning. A modern data platform enables engineers to meet the growing demands of data from their organizations.
When easy enough to use, it could be your “engineer in a box” allowing you to operate your data with analysts in the front rather than depending on engineers. This efficiency increases the number of pipelines a data engineer can build and support. In addition, we have spoken with Data teams who adopted a modern data platform and saw the ramp-up period for new engineers accelerate from an average of 6 months down to a few weeks.
4. Lower costs
Managing multiple data sources, a complete data architecture, and different tooling comes with its costs. These costs not only include buying licenses for separate tools but also the salary of each person on the data team (FTE) and their ability to run processes efficiently to deliver business value. What does this look like in practice?
We broke down the average cost of a Modern Data Stack vs. the average cost of a Modern Data Platform.

On average, we discovered that organizations were investing approximately $130,000 USD in the components of their modern data stack, while a Modern Data Platform averaged around $65,000. It’s important to note that these figures exclude the costs associated with full-time employees (FTEs) responsible for integrating the various components of the modern data stack. According to GlassDoor, the average salary of a data engineer in the United States is $144,389. Our findings indicate that data teams adopting a data stack approach often require an additional data specialist to manage the setup and maintenance of data tools, whereas teams adopting a platform approach can streamline operations, potentially saving on headcount and delivering end-to-end data pipelines within hours.
Data Platforms Should be Closed But Open
Traditionally, on-premises data platforms were closed in nature, making it challenging to switch to other platforms and serve diverse use cases. This had advantages, such as centralizing data governance, security, compliance, and role-based access control (RBAC). However, it also limits the flexibility of your data platform.
Data teams should aim to find a balance between control and openness. The market will continue to trend towards platforms building upon the initial success of MDS. The key is to ensure that unlike in legacy data platforms, the platform is closed but open: platform-level control with the power to enhance the setup/swap out tooling if needed.
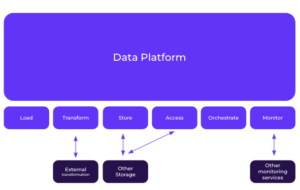
But what do we mean by closed but also open?
As first mentioned by Timo Dechau, in this post during the summer of 2013,
A closed but open approach lets you benefit from the best of both worlds with the governance and control you need to manage processes efficiently and ensure standards are being followed while being able to enhance and tune if needed with additional tools/services for specific functionalities.
This combo is the key to enabling organizations to adopt concepts such as Data Mesh providing teams the freedom they need to manage their data while ensuring the control is still there.
A great way to think about this is to ask yourself, “What pieces of my infrastructure should be decentralized, and what would make more sense to centralize?”
For each organization, these answers will vary, but over the past year, we have seen some common themes emerge.
Essential data management capabilities like data governance, security, and control over consumption costs should be uniform across the board and centralized in a single pane of glass. If you are working at a larger organization, you have likely experienced (or know someone who has) the pain of managing governance across teams, which only grows in complexity as your use cases and team grow.
And, which parts of your data architecture should be decentralized?
Data product teams should have an area where they can work and have governed connections and sources, and build data pipelines themselves to alleviate some of the bottlenecks we mentioned earlier to reduce the “stack”-like the nature of the modern data stack.
What is Rivery?
Rivery is a SaaS ELT modern data platform that simplifies building and maintaining end-to-end data pipelines.
Rivery can ingest data from any source via no-code pre-built integrations or custom connection
integration. This ingestion isn’t only to bring SaaS apps, databases, or file data into a lake or
warehouse but also back into business applications via Reverse ETL. From there, Rivery allows you
to transform your data using SQL or Python inside the platform, or by leveraging a data
transformation tool like dbt.
For example, you can trigger a transformation right after an ingestion pipeline and then trigger a Tableau extract refresh to make sure Tableau’s data is up to date.
As a platform, Rivery also helps with the development life cycle with native versioning and
deployment automation, better management of the data operations with full monitoring of the
pipelines activities as well advanced governance.
The platform breadth enables Rivery to deliver a marketplace of pre-built solutions that can help
accelerate end-to-end solution deployments. As mentioned earlier, Rivery is also open for
integrations with the rest of the ecosystem so you can formulate your ideal architecture. One of our
core principles at Rivery is that elements such as ingestion, transformation, and orchestration are
seamlessly integrated within Rivery but you can also integrate other tools and processes with Rivery.
We designed our platform to ensure that data users not part of the centralized data team can also
self-serve and build their own pipelines. This requires great ease of use, reusability, customization
abilities, and collaborations. And of course, we ensure it all works at scale with full transparency
and governance by the centralized data team.