





















Move data in and out of Databricks faster

In today’s data economy, survival comes down to business value and how quickly it can be delivered continuously.
To make this happen, integration and bidirectional flow of data between disparate data sources is required. A SaaS platform that offers these capabilities plus Reverse ETL ensures that the data lands in the storage layer and seamlessly syncs back to operational systems – where it is put to use.
The result? Actionable data and insights are delivered to the right people at the right time, speeding up accurate decision-making. When you combine a SaaS platform with these capabilities, together with a storage system like Databricks, you’re one step beyond the Modern Data Stack.
Enter Rivery and Databricks
Databricks is revolutionizing how we monetize data assets, almost shoving us through the door of innovation. Unity Catalog and bleeding edge AI/ML capabilities are liberating Data Engineers, Analysts, and Scientists alike from legacy policy restrictions, hardware limitations and data accessibility issues. As a result, Databricks has built a passionate and loyal fanbase.
Rivery is changing what the world calls “ETL” and what businesses should expect from vendors and data integration between systems. Our platform is designed to maximize the impact of engineering time by generating value, rather than connecting dots. Rivery’s differentiators in achieving that impact are in security, flexibility, and cost. To put those into context, we’ll first share baseline functionality that Rivery has and that we believe all modern data operations tools should have, and then we’ll dive deeper into each of them.
So, what are Rivery’s “table stakes” for a data integration platform?
- Perform all forms of data integration and transformation: ETL, Reverse ETL, and Data Activation
- Provide a composition layer to coordinate data orchestration(s)
- Work in hybrid-cloud environments; not beholden to one provider or implementation scenario
- Not have to install software patches, firmware upgrades, or remember to turn the switch off before we leave.
- Have safety built-in: separate environments for code promotion/demotion, security standards and controls, real-time alerting and monitoring
- Tight integrations and custom connectors that drive value rather than frustration and confusion
- Seamless customization including use of dynamic variables throughout data pipelines.
- Nearly infinite,scalability (no provisioning additional instances or modifying the sizes)
- Rivery was built from day 1 with these “table-stakes” functionalities in mind.
Security
For any company that operates in the Cloud, security is a big concern. As data privacy and sharing laws become more stringent and punitive, companies need to be proactive and strategic about how they manage data assets. Data processing platforms such as Rivery and Databricks have made data security core to their offering.
Both Rivery and Databricks offer numerous options to protect your data from its acquisition to its storage and retrieval. Once data is housed within the Databricks Lakehouse, it is under your lock and key. Utilizing the Unity Catalog ensures visibility into all data assets – regardless of where they are – all in one place, while managing and auditing access and usage as well. As they say, the best disinfectant is sunshine.
What about the data before it is governed by Unity Catalog?
Rivery is known for time to value and reduction of complexity and inefficiency, traits which are often burdened by security protocols and policy. Knowing this, Rivery has taken a security-first approach to data processing and management. Always-on encryption at rest and in transit, secure network protocols (SSH, SSL, VPN, Private Link), and an ephemeral server architecture are security fundamentals that Rivery and Databricks both employ.
Custom File Zones
“Big Data” has forced Data Engineers as well as ETL/ELT companies to employ stream or smart batch-based methodologies to keep up with demands and volumes. In order for this data to be efficiently loaded, it first needs to land in a staging area. With data volumes so large (and growing) there really isn’t a reasonable alternative – data must be staged before loading.
The most common solution to this problem is to store/stage extracted data in files, in formats that are mostly ubiquitous in Cloud Storage Containers (S3, GCS, Azure Blob Storage) before they are loaded into their destination. For most data processors this staging happens in their network infrastructure, which can be a red flag (also a legal and policy violation) because data ought not be persisted anywhere beyond the data owners’ network.
Where Rivery differs is with Custom File Zones, which allow customers to use their own Cloud Storage as a staging area, giving them full control over the entire data processing life cycle. The policies, access, etc. are all configured and maintained by the customer – List, Read, Write is all that Rivery needs to access your Cloud Storage Container and just like that, your data (and governance policies) is still yours and there’s no legal implications to worry about.
In addition to our Custom File Zone support, Rivery is currently building native support for Volumes in Databricks Unity Catalog. This feature would enable users to stage the data in a Volume in Databricks Unity Catalog to allow for better discovery, governance, and lineage tracking for their data in Unity Catalog.
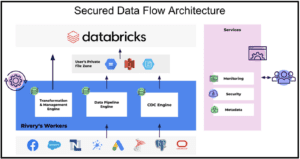
Flexibility
Traditionally, “data integration” solutions started with one source and a common destination. Immeasurable time and effort was wasted abiding to software vendor’s data dogmatic processing paradigms, which were centered around maximizing seats and senseless complexity.
Teams today cannot afford the perspective of antiquated ideologies, whose “best practice” guidelines are merely a tool to further entrench themselves into the enterprise. The demands are too great, the sources too diverse, and the budgets are heavily scrutinized. Teams need to be nimble and empowered to develop their own situation-based patterns for data integrations and processing. With technology changing so rapidly, adaptability and flexibility are crucial to success.
This reality has shaped Rivery into delivering on an almost contrary philosophy. For Instance, rather than limiting functionality to a single target (that is pre-determined to be a CDW) – regardless of the source – Rivery supports targeting data anywhere. In the context of Databricks, Rivery can manage data between Catalogs and even invoke Databricks APIs to run a Databricks Notebook. Once data is loaded, a summary email about the processing can be sent automatically. With hundreds of native connectors, Change-Data Capture (CDC) for database replication (a HUGE time saver) and connect-to-any-REST-API functionality, the capabilities are vast.
The great debate over where transforms occur and who does them is also moot to Rivery. We know you are going to transform your data; that is where the value comes from. Given our Cloud paradigm, we embrace push-down SQL transformation to Databricks in addition to ephemeral Python transformations. Or simply add a call in a Logic River to an external service to perform the transformation. Again, it’s up to you.
With trending terms such as “Data Mesh” and “Data Fabric” we found that something as ancient as email notifications are absolutely necessary to almost every data orchestration. With monitoring and notifications built-in, we expand on flexibility with responsiveness. While notifications are “table stakes” today, this functionality continues to empower users to quickly diagnose and respond to any potential issues.
That’s the flexibility in the build phase, but what does flexibility mean as usage grows?
With the Rivery’s Environments functionality, teams build in individualized workspaces. This means that diverse teams can use the Rivery platform simultaneously while controlling granular access to non-permissioned projects. Admins can modify environments and user permissions as statuses change. Environments can be used to separate internal workspaces by department, team, and even development lifecycle (Dev, Test, Stage, Prod). Deployment packages can also be used to merge Rivery pipelines from one Environment into another. With the ease of use and flexibility of Environments, you’ll be able to maximize access control, change management, and pipeline organization to fully unlock the potential of your data operations.
Cost Management
Time to value. We hear that sentence multiple times a day, but rarely do we drill into what the actual impacts are. The primary way Rivery reduces the time it takes to achieve value from data integrations is by making them simple. The easiest way to solve a difficult problem is to isolate the difficulty, and we believe that engineers should be using their brains to solve difficult problems rather than performing commoditized activities such as mapping data types, coding loading strategies, dissecting JSON outputs, or building integrations and fact tables from scratch. Rivery solves this by providing prebuilt Kits and Predefined Reports to allow engineers to reuse common templates from other teams and even companies. In all cases, it is the isolation of simple versus difficult that makes Rivery so efficient throughout the project lifecycle.
Transformations are where the most complexity and nuance exist, and also where the most undiscovered value can be found. This is the reason we are so focused on minimizing the boring and repetitive tasks engineers and operators are subject to. If we can move just 20% of an engineers’ efforts from copy-paste activities (and software updates and hardware management) to tasks focused on innovation, exploration or simply more transformation, we end up with a day per week where an engineer is DEDICATED to providing value. Beyond push-down SQL, file conversions, and Python transformations, Rivery can orchestrate transformations in external platforms (such as Databricks) via API, enabling event-driven composition of Enterprise data.
Another way Rivery tackles the data integration problem (beyond the metadata interrogation, auto-mapping of schemas and so on) is with breadth and flexibility. Additional value is created and realized by investing in one integration platform as opposed to a smattering of point solutions. Again simplifying the problem by having data ingestion, orchestration, notifications etc. all in the same platform increases quality, reduces labor inefficiency and software contract “negotiations”. Isolating platform duties and standardizing will reduce the total number of applications to support and will inevitably make the enterprise more efficient, nimble and save money as a result.
Measuring cost to value becomes a nearly trivial endeavor with consumption-based pricing, which is one of the reasons the most successful companies today seek out this methodology. When simplifying the problem, It becomes easy to measure, manage, and attribute actual costs to integration efforts. Managing cost is much more difficult when trying to predict how many primary keys are changing daily. Or how to procure and manage seat and adapter licenses when a new project comes along, or scheduling the shut down and start up of development and test environments. It’s simple. If resources are consumed, so are credits. If no resources are consumed, no cost. Easy.
Biggest takeaway
Our customers typically find initial savings greater than 30% when migrating from competitors’ solutions. Anyone can fill out this form for a ballpark pricing comparison of Rivery versus our main competitor. This doesn’t include the efficiencies gained over time or additional integration capabilities and value generated by optimizing engineering time, which further increases the impact of a successful deployment.
There really is a lot to take into account when considering a data integration solution. In the rapidly evolving data integration space, it can be an overwhelming choice. Security and Cost are always a part of the decision, and they should be. Simplicity and flexibility are now also at the top of the list, considered imperative to evaluate because they are vital to the success of every team. With so many demands on data assets and teams, underdelivering is not an option.
Can't miss insights



Minimize the firefighting. Maximize ROI on pipelines.

