





















How to replicate or sync Snowflake data anywhere

Recently, we’ve witnessed a surge in demand for “Snowflake as a source” integration. Fueled by the need to seamlessly move data from Snowflake into different systems, the use cases include transferring data to another data warehouse, cloud bucket, SFTP, a SaaS application, or even another Snowflake instance. Check out the full list below.
Top Snowflake data movement requests
Replicate Snowflake data in a data lake: Snowflake to S3
Migrate Snowflake data to another data warehouse:
- Snowflake to Databricks
- Snowflake to Snowflake
Write Snowflake data to files: Snowflake to SFTP
Reverse ETL:
- Snowflake to Salesforce
- Snowflake to HubSpot
- Snowflake to any other SaaS application
Let’s jump right in and see some real examples of how Rivery currently lets you address these different use cases using Logic Rivers. With Logic Rivers, one can leverage a connection to Snowflake which is using our “Snowflake as a target” connection. This allows us to query the data out of Snowflake and push it into other systems. Since the connection is based on our “Snowflake as a target” connection, the user requires write permissions as well to the Snowflake database.
Snowflake to S3
Moving Snowflake data to S3 is the most straightforward one, you can complete the entire replication process in five simple steps
1. Create a Logic River:
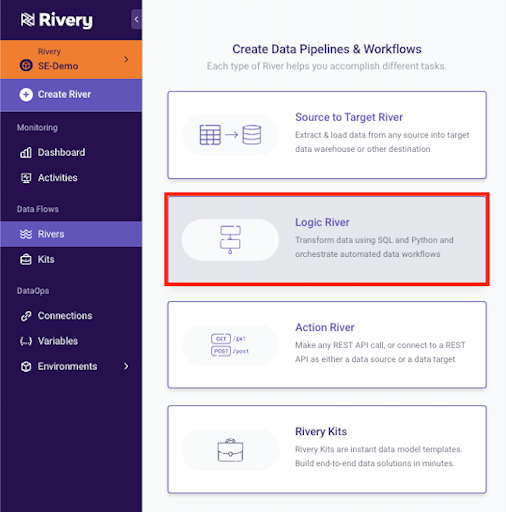
2. Select a SQL/DB Transformation Step:
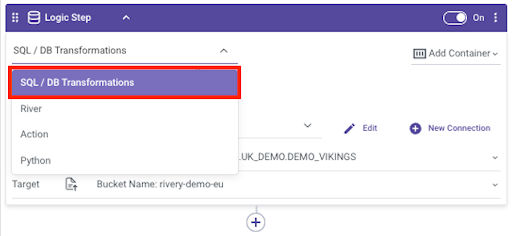
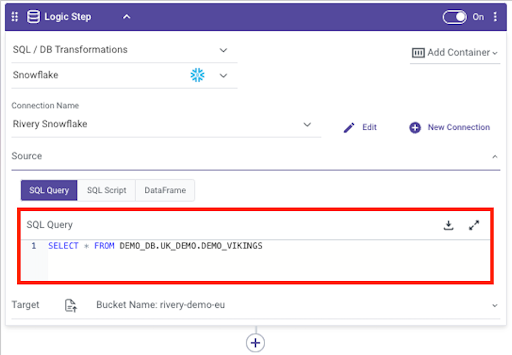
3. Write the SQL Query that will be used to extract the data wanted:
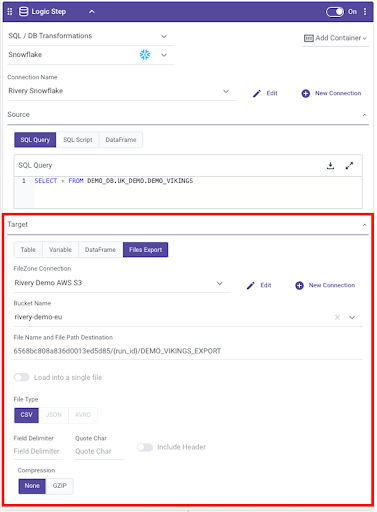
4. In the Target section, select “Files Export”. You can then select your S3 connection, the Bucket Name, and customize the File path and File name Destination.
Here, I used the River ID and Run ID as sub-folders in my path and the file name is “DEMO_VIKINGS_EXPORT”:
5. Run the river and see your data in S3:
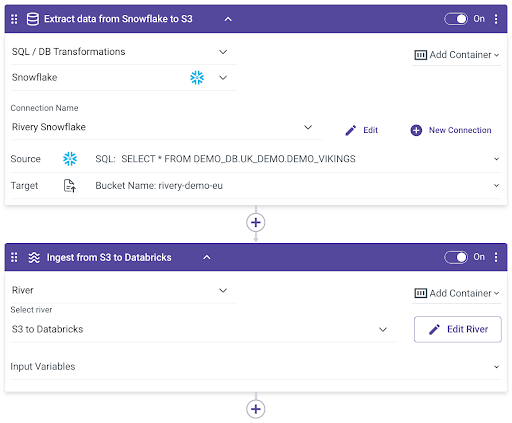
Snowflake to Databricks
For Databricks users that are on AWS, you can easily move Snowflake data to Databricks with S3 as an intermediary:
- First, export the Snowflake data to an S3 file as seen in the first example “Snowflake to S3”.
- Then, create a classic “Source to Target River” to move data from S3 to Databricks.
- Finally, trigger that Source to Target River execution as the next step under the same logic river we used to export the Snowflake data to S3:
Similar steps can be applied if you wantto move their Snowflake data into Google BigQuery.
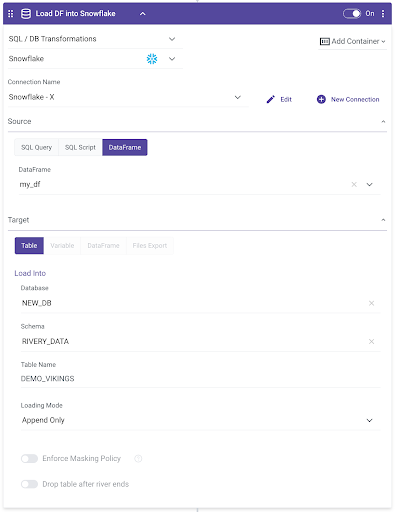
Snowflake to Snowflake
If you need to move data from one Snowflake instance to another Snowflake instance, you can apply the same steps as above – “Snowflake to Databricks”. Alternatively, you can use Rivery’s Dataframes:
- In the first step of a Logic River, query Snowflake data and save it to a Rivery Dataframe (this is staged in an S3 bucket, that can be customized to be a proprietary S3 bucket. You can create it beforehand in the DataFrame’s panel on the right-hand side panel):
- Add another logic step to load the data directly from this Rivery DataFrame into Snowflake:
Similar steps could be applied if you want to move their Snowflake data into Amazon Redshift.
Snowflake to SFTP
To write Snowflake data to an SFTP, you can use a Logic River with 2 steps and this time, including a Rivery Python step as well:
- Use a SQL Query to query the data to extract, and save it in a Rivery Dataframe.
- Use a Python step to push the Dataframe content to the SFTP:
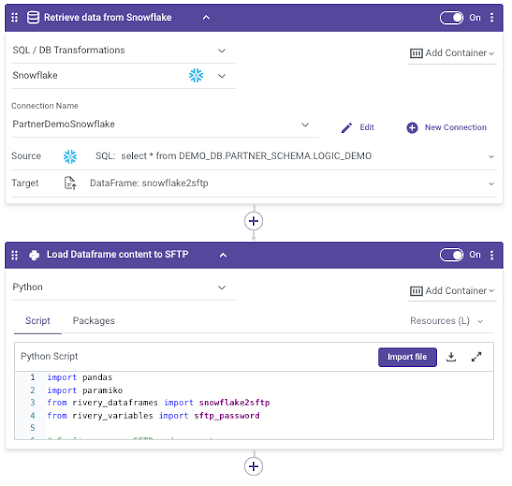
As you can see, the second step is leveraging Rivery’s Python capabilities. In the Python script, use the Paramiko library to seamlessly connect to SFTP. You can either use a set of username/password to connect (and if so, we recommend storing those as encrypted variables) or an SSH key. We save the Rivery Dataframe in a local CSV, open a connection to the SFTP, push the CSV to the SFTP, and voilà!

Snowflake to Salesforce
Syncing Snowflake data with business applications such as Salesforce and others for Reverse ETL, can be conducted with Rivery’s Action Rivers, orchestrated within Logic Rivers. Ready for the best part? Rivery has pre-packaged kits, specifically for Snowflake. These kits include ready-made data pipelines to sync data back into Snowflake.
You can find the right kit based on your use case or modify the kit template to meet your unique needs:
- Create Salesforce objects (i.e. create a new opportunity)
- Update Salesforce objects (i.e. modify the Salesforce lead last contact date)
- Create/updates Salesforce objects in bulk (i.e. instead of doing it record by record)
Snowflake to HubSpot
To help you reverse ETL data into HubSpot, we have pre-packaged a kit. Simply deploy the kit in your account and follow the instructions.
Snowflake to any other SaaS application
You can use Action Rivers to post data into the REST API endpoint. You can easily construct Logic Rivers to query the data from Snowflake and push to your desired application via the Action Rivers. To get started with your own Reverse ETL pipelines, either follow the pattern of the different kits mentioned above or check out our docs and this video.
Let’s wrap it up
From what we’ve seen this year, I expect that in 2024, we’re going to see a rise in demand for more cloud data warehouses as a source. When our users speak, we listen. So far, we’ve added Google BigQuery as a source and Amazon Redshift as a source to our integration listing for DWH as a source. Snowflake as a source is set to be released next. Till then, please let us know if the methods above help with your Snowflake data extraction.
We’d also love to hear about any other use cases you may want to address with Snowflake as a data source. At the end of the day, our job is to make your life a whole lot easier, so that creating “source to target” data pipelines from Snowflake to any target will be a breeze for you.
Can't miss insights



Minimize the firefighting. Maximize ROI on pipelines.

