Salesforce Create/Update Objects – Bulk – Snowflake

Last published
2023-06-05
Categories
Sales Crm
Type
Data Activation
Integrates with


The salesforce create/update objects – bulk kit allows one to query a table representing salesforce records in snowflake and create/update them in a salesforce account using a “reverse-ETL” process.
This kit extends the salesforce – create/update objects kits by allowing you to send records in bulk rather than one at a time using the salesforce-bulk python library.
This Kit includes…
An action river to authenticate into the salesforce api and pull the needed access token.
A logic river with the necessary steps to send records from snowflake to salesforce via python script.
Configuring this Kit for use:
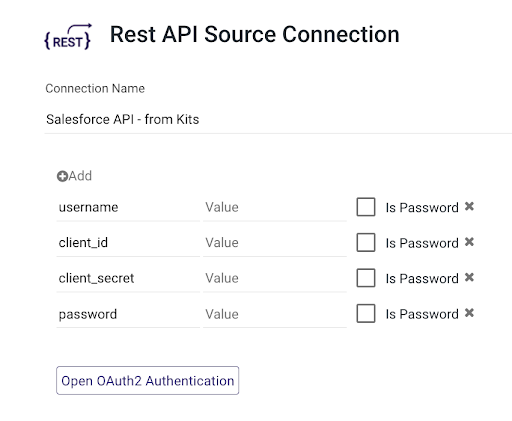
One must create a connection to their salesforce instance with the needed parameters in the connection details:
One must create a connection to their cloud data warehouse and in the first logic step in the first container, titled “Extract new salesforce records from cdwh.”, and write a query that selects the records from a table. The result of the query must return a set of records that match the expected format for the object that you want to create exactly, including all field names and the proper datatypes expected by the object that you expect to push to in salesforce.
WARNING: The queried fields must match the expected fields for that object EXACTLY, the kit will not work otherwise.
In the first step of the second container, one must write a query to select all records that need to be updated in salesforce. This query must only select records that exist already in salesforce and have one column that contains the salesforce ID’s of the records that you wish to update. This column must be called either ID or customExtIdField__c.
If updating objects, one of the queried fields must be called ID, or customExtIdField__c, and must refer to the salesforce ID of the object that you want to update.
If you intend to only use this kit to create and/or update objects (not both), you can toggle off the container that is not relevant.

Ensure that the total size of the records is within the allocated compute resources of the python cluster that is being called. The default “Medium” size comes with 2GB of RAM. Using an approximation of 1MM rows of data = 100mb. This documentation contains additional resource size references as well as their corresponding compute costs: https://docs.rivery.io/docs/python
Variables
In this kit, there are variables associated with the salesforce instance that need to be updated with the proper values in the logic river. Once can update these values by clicking the “variables” button on the top right.
These are the variables that need to be updated:
- Note that these three variables are the ONLY ones that need to be user-set, the other variables will be dynamically populated and need to be left empty in the UI.
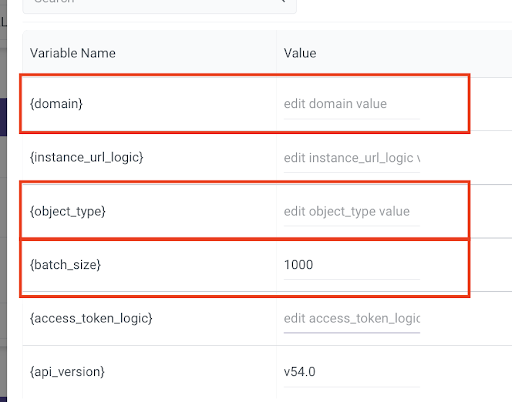
{domain} – refers to the salesforce domain that you want to create these new records in, should be the highlighted part of your organization’s salesforce url:


{Salesforce_Alert_Group} – Refers to a comma separated list of email addresses that you would like emails sent to in case of failures or warnings for the river in question.
{object_type} – Refers to the name of the object type whose records you want to create in Salesforce. For ex: the value of object_type can be “Account”, “Contact”, “Opportunities”, etc
(Optional) {api_version} – Refers to the salesforce api version that you wish to use, v54.0 is the default.
(Optional) {batch_size} – This variable indicates the size of the individual batches of records to send to the salesforce-bulk api. By default this is set to 1000 but may need to be adjusted for longer records to stay under api limitations on character limits.
In addition to the variables in the logic river, there are certain environment variables that you will need to update as well. These variables are:
{Database_Snowflake_SF_Bulk_Create} – Name of the database where you would like the env activities table to be created.
{Schema_Snowflake_SF_Bulk_Create} – Name of the schema in the snowflake database where you would like the env activities table to be created.
{Mail_Alert_Group_SF_Bulk_Create} – Comma separated list of email addresses that you would like to notify upon failure of the river.
Dataframes
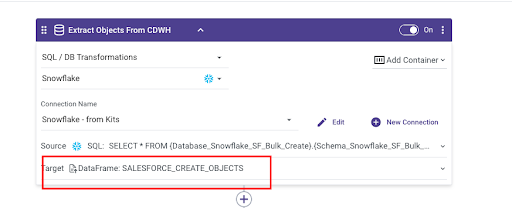
One needs to create two rivery dataframe objects in order to hold the results of the SQL Query in the two containers of the logic flow.
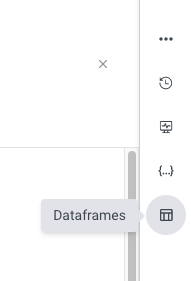
To create a Rivery Dataframe, go to the menu on the right hand side of the logic river UI and click the dataframes icon:
Click “+Add”.
Name the dataframe SALESFORCE_CREATE_OBJECTS and click “Add”:
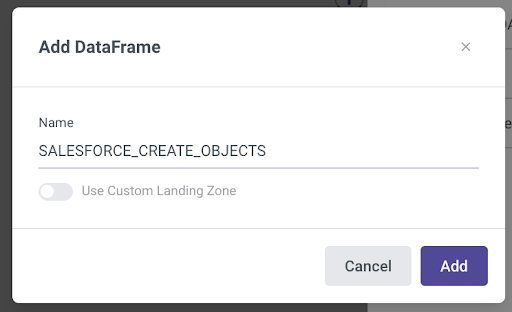
Note that if you are using a custom landing zone or desire to, you must follow the steps laid out here to enable access to your s3 bucket: https://docs.rivery.io/docs/python-dataframe
Repeat steps 1-4 for another dataframe, titled SALESFORCE_UPDATE_OBJECTS and set it to be the output of the SQL step in the second container (step titled: “Extract salesforce records to update.”)
Connections
Kits are imported with ‘blank’ source and target connections. In order to use the template, you have two options:
Swap out blank connections with existing connections
Add credentials to the blank connections that come with the imported template.
Have questions about this kit?
Send an email to helpme@rivery.io with the title “Help – Salesforce Create/Update Objects – Bulk Kit”