





















Database Migration With Rivery –
The Ins and Outs.
Introduction
In today’s data-centric world, efficient database management, specifically data extraction through migration or replication, is critical for businesses aiming to leverage their data assets effectively. This technical whitepaper explores Rivery’s comprehensive database migration solutions, offering insights into its architecture, supported databases, robust security measures, and flexible database connection options.
Rivery’s Philosophy
Rivery focuses on simplifying database migration to cloud data warehouses, lakes, or lakehouses through its Software as a Service (SaaS) architecture. The goal is to make database migrations seamless, quick, and reliable, requiring minimal maintenance or infrastructure setup overhead for organizations.
Simplified Database Migration
Rivery securely connects to your source database to replicate data using your preferred security method, without requiring an additional installation of a dedicated agent. This eliminates the need for organizations to provision additional hardware for an agent, size the required capacity, and manage version changes, as everything is handled by Rivery along with your existing networking connections.
Beyond the secured connection to your source databases, Rivery’s automated solutions facilitate data extraction, transformation, and loading into target destinations. This process is simplified in various ways, including ease of setup for streaming and batch replication methods, built-in handling of schema changes (schema drift) within source databases, easy monitoring to ensure data consistency and reliability throughout the replication process, and more.
Rivery’s Architecture
Operational database data extraction involves querying and moving data from databases like MySQL, PostgreSQL, SQL Server, Oracle, or MongoDB to lakes, warehouses, and lakehouses like AWS S3, Google Cloud Storage, Snowflake, Databricks, or Google BigQuery.
Rivery’s cloud-native architecture is designed to ensure data can flow seamlessly, at scale, and securely from different data sources to the right targets. The scalability of this data flow process, ensuring Rivery can handle large volumes of data to move and at high frequency, is centered on an auto-scaling architecture. This architecture involves dedicated clusters for specific tasks, ensuring efficient resource allocation for any data volume and refresh rate. Pods within these clusters listen to queues, receive tasks, and execute processes accordingly. Security features include encryption for data at rest and in transit, encrypted customer connection properties using KMS, and hashed user login data. Secure connections to Sources and Targets are supported through options like Private Link, VPNs, SSH Tunnels, and Reverse SSH.
Rivery enables data extraction from databases to targets using standard batch SQL queries or Change Data Capture (CDC) methods, supporting a range of efficient data handling for different scenarios.
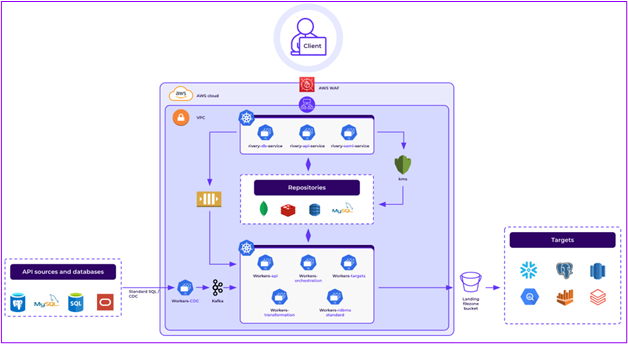
Rivery’s data replication architecture
Data Extraction Methods
Rivery offers two primary data extraction methods: standard SQL-based Extraction and Change Data Capture (CDC). Standard SQL-based extraction offers flexibility and control, allowing for customized queries, selective column extraction, custom expressions, schema drift adaptivity, and row filtering. On the other hand, CDC excels in near-real-time synchronization, capturing incremental changes swiftly, and maintaining data integrity without overburdening the database. Not sure which extraction method is right for you? Learn more.
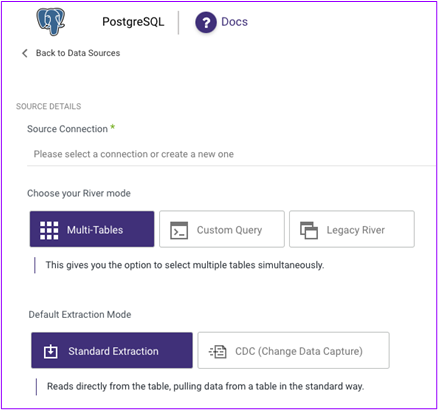
Selecting the replication mode within Rivery
Standard SQL-based Extraction
Standard extraction in Rivery offers users 2 primary extraction modes:
In Multi-tables mode, the process begins with a connection test to identify potential errors. Upon successful testing, Rivery proceeds to the metadata reload phase. Here, Rivery leverages metadata detection functions customized for the chosen DB dialect. This step involves detecting schemas, tables, columns, and their metadata, while also categorizing fields based on Rivery’s type handling configurations (for example, consider the following scenario). With access to the metadata of the database schemas, users can conveniently select tables (and even specify columns for replication) from a provided list. Rivery then advances to the ‘run River’ phase, executing tasks based on the chosen tables and columns.
Alternatively, users have the option to use the custom query mode, allowing them to input a custom SQL query for Rivery to seamlessly incorporate into its operations.
Each data flow involves connection checks, data parsing, statement command preparation, and execution, followed by saving the extracted data as CSV files in a File Zone.
To handle large data volumes efficiently, Rivery employs a “Migration by Chunks” approach. It automatically processes table information data and divides it into manageable data chunks based on the table’s size, primary keys, partitions, and indexes without user intervention. Additionally, Rivery automatically manages database connections to avoid timeouts during large data migrations and ensures that database connections are closed when not in use.
Change Data Capture (CDC)
Change Data Capture (CDC) tracks changes in a source database, usually by reading that database’s log file, and automatically transfers those changes to a target dataset, effectively eradicating data silos. Changes are synced instantly or nearly instantly. In practice, CDC is often used to replicate data between databases in near real-time with minimal impact on the source database.
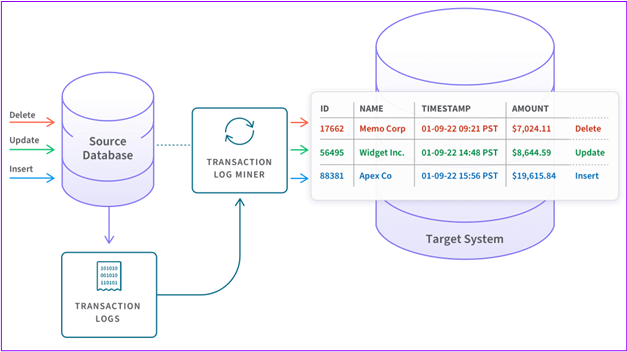
CDC process
Rivery developed an architecture to significantly optimize CDC efficiency, designed to overcome common challenges encountered with open-source CDC solutions.
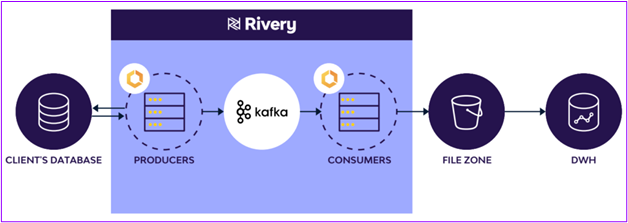
Rivery’s CDC process architecture
With Rivery’s CDC, the user will define in Rivery which tables to replicate to the target and whether to migrate the history of those tables or start the replication from a certain point in time. Once defined, the process works as follows:
- Rivery uses a stream to retrieve the database logs via a Producer process. This process reads the database logs and pushes its messages to a Kafka topic per table.
- Consumer processes subscribe to Kafka topics, handling each message and directing it to the appropriate ‘File Zone’ (cloud storage services such as AWS S3, Blob Storage, or Google Cloud Storage) in files. The files are then stored in the File Zone in chronological order based on the log read time.
- At the end of the process, Rivery transfers the data from the File Zone to the data warehouses or lakehouse according to your defined schedule (to optimize potential compute costs on the receiving target as per your business requirements). Rivery’s process also ensures duplicate removal to provide the most updated row in the log to the target. This, along with other metadata processes in the flow (such as data type mapping and schema drift handling), makes the entire data pipeline management seamless.
You can delve into more comprehensive information regarding our streamlined CDC process.
Security Measures
Security is a top priority for Rivery, and several measures are implemented to ensure data confidentiality, integrity, and availability.
Encryption
Data exchanged between Rivery and supported databases is encrypted using standard industry protocols such as TLS, ensuring secure transmission. Rivery establishes connections with any API, whether acting as the Source or the Target, using TLS (HTTPS) by default, a configuration verified by our client. If the database is set to default to TLS (SSL), Rivery aims to leverage the default TLS settings. Clients desiring specific TLS certificate validation can opt to use the SSL configuration checkbox (when setting up the connection in Rivery) and provide their designated TLS certificate.
Access Control
Rivery enforces strict access control policies, enabling organizations to define roles and permissions for secure platform and database access.
Compliance and Certifications
Rivery adheres to industry best practices and complies with regulations such as SOC 2 (Type II), GDPR, ISO 27001, and HIPAA. The platform undergoes regular security audits and holds certifications to demonstrate its commitment to data security and compliance.
Custom File Zone
Before loading data into a data warehouse or lakehouse, data is staged within a File Zone (cloud storage services like AWS S3, Blob Storage, or Google Cloud Storage). By default, this cloud storage is managed by Rivery, where data is retained for 48 hours in case it needs to be reprocessed. Rivery provides users with an option to define a Custom File Zone within their organization’s own File Zone. This ensures that data stays within their cloud network, enabling data lake capabilities and defining retention policies crucial for handling sensitive data sets. Learn more.
How to Choose the Right Database Connection Option
Rivery offers various database connection options tailored to different security and network requirements:
Whitelisting IPs
The IP Whitelisting method simplifies connections by including Rivery’s IPs in the client’s network access rules. However, it’s considered less secure because it mandates granting access to the data source from Rivery’s IPs over the public internet, requiring the data source to have internet access and a reachable public IP address. In most cases, this is the least preferred option. To enhance security, SSL (Secure Sockets Layer) or TLS (Transport Layer Security) establishes encrypted communication between Rivery and the data source, ensuring privacy and security during data transfers.
SSH Tunnel
SSH tunneling is a technique for sending network data across an encrypted SSH connection. It can be used to connect resources from external networks to an internal network without exposing internal resources to the Internet. In many Rivery use cases, the SSH tunnel is used to provide safer and encrypted access from Rivery servers to internal databases to retrieve data.
Reverse SSH Tunnel
Reverse SSH tunneling is a method that enables secure connections to a device behind a firewall or NAT from a remote location. The process of setting up a Reverse SSH Tunnel using Rivery facilitates remote access to services on the local machine. In essence, Reverse SSH establishes a secure link from a remote machine to a local one, overcoming network barriers like firewalls or NAT. Rivery provides customers with a dedicated VPN and account, actively listening on a specified port for incoming SSH connections. The client network, where the remote machine resides, initiates an SSH connection with the Rivery-provided account, creating a secure tunnel through which traffic can securely flow. This setup effectively bridges the Rivery Workers Account and the Customer Connectivity Account, enabling remote networks to access services as if they were locally hosted.
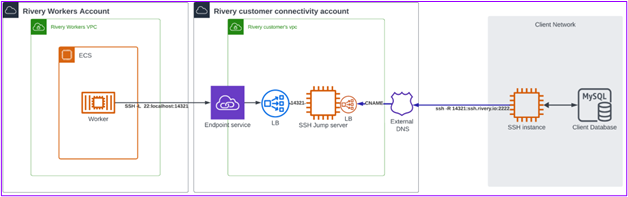
Reverse SSH network diagram
Virtual Private Network (VPN)
A Virtual Private Network (VPN) is a network technology that establishes a secure and encrypted connection over a public network, such as the Internet. The primary purpose of a VPN is to enable users to securely access and transmit data across public networks as if they were directly connected to a private network. By doing so, VPNs offer privacy, data integrity, and confidentiality by encrypting the traffic between the user’s device and the destination network. This method is recommended for scenarios prioritizing security over performance and where a VPN solution is already the preferred method by internal network admins.
AWS PrivateLink and Azure Private Link
Private Link is a secure and scalable way to access services through a private endpoint within a virtual network. By using Private Link, traffic between your virtual network and the service travels over the AWS/Microsoft backbone network, rather than over the public internet.
The below flowchart is designed to help you choose a recommended connection method for your organization. Please consult with your security/network admin as needed to validate the recommendation in your scenario.
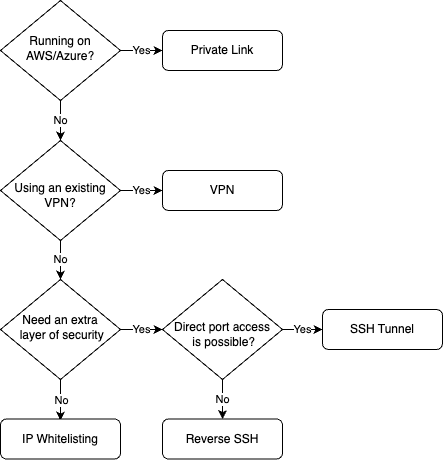
Recommended connection method
Supported Databases
Relational Databases (RDBMS)
Rivery supports a range of popular relational databases that are suitable for transactional and analytical workloads, offering robust data storage and querying capabilities. Supported databases include:
- MariaDB (Versioned tables, and Standard extractions)
- Microsoft SQL Server (both CDC, Change Tracking, and Standard SQL)
- MySQL (both CDC and Standard SQL)
- Oracle (both CDC and Standard SQL)
- PostgreSQL/Aurora (both CDC and Standard SQL)
NoSQL Databases
In addition to relational databases, Rivery supports various NoSQL databases. NoSQL databases excel in handling flexible data models, large data volumes, and low latency. The supported databases include:
- ElasticSearch
- Google Cloud Datastore
- MongoDB (both CDC and Standard SQL)
Data Warehouses (DWH)
In addition to relational and NoSQL transactional databases, Rivery extends its support to replicate data from dedicated data warehouses (DWH) using Massively Parallel Processing (MPP) architectures. This capability is extremely useful in cases where organizations need to migrate data from one DWH to another or continuously sync data between DWHs when using a hybrid DWH approach. Supported databases include:
Conclusion
Rivery offers a flexible and pain-free database migration service built and operated based on a robust security model that is informed by industry best practices and validated by third-party security experts. Rivery understands how important your data is and takes the responsibility to move and protect it very seriously.
