





















6 Musts for Headache-Free Change Data Capture (CDC)

At Rivery, we’re all about data, specifically – managing the data pipeline lifecycle. So, it’s no surprise that part of what we need to help organizations do is to not only move data from point A to point B. What we also need to be able to do is to help them move updates and changes from point A to point B in the most efficient, friction-free, and fastest way possible.

The need for replication speed
Moving data from relational databases (point A) to data warehouses, data lakes, or other target databases (point B), and syncing between the two whenever there’s a change has traditionally been executed through batch data replication.
But batch data pulling has its limits – it requires additional computing, provides insufficient inputs on the history of deleted rows, and generates higher latencies than we want.
To overcome these limitations organizations have moved away from batch or bulk load updating to incremental updating with change data capture.
In comes CDC
CDC speeds up data processing by eliminating the need for full-scale database replication in the ETL/ELT pipeline, and by creating an analytics database as a separate copy of the production database.
Because it only deals with changes to the logs, CDC eliminates the need for ongoing database replication using the database engine, thereby minimizing the resources required for ETL/ELT processes.
And since it deals with new database events as they occur, it enables real-time or near-real-time data movement. As such CDC is ideal for near-real-time business intelligence as well as for cloud migrations.
The CDC challenge
There are a number of commercial and open-source CDC solutions out there, but these too come with some noteworthy challenges.
It’s important to ask these questions before selecting the approach:
- Error messages: does the platform deliver clarity for quick and efficient remediation?
- Scale: does it work with all of your database types?
- Day After: Does the solution is easy enough to test, check and configure when something wrong is happening?
- Database Topologies support: does it support your DB topology? Does the solution know how to handle replicas, always-on, multi-masters DB, etc…?
- SSH tunnels and other connection topologies: does it support SSH connectivity and other connectivity best practices?
- Use cases: can it handle all your use cases, db types, tables, column data types, etc.?
A new approach to CDC
Since we were hearing from many organizations around the world that the solutions out there were not providing them with the requisite capabilities and support, we at Rivery went out to develop a CDC solution that would provide the support required.
1. The programming language we chose
The Rivery CDC solution was created with Go, which offers many important advantages, including:
- Multithreading out of the box
- Compatibility with multiple channels
- Great support for I/O
- Stability
- Flexibility
- And it’s very light
2. The architecture
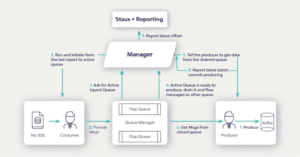
We built an architecture that drives high rates of CDC efficiency. For example, the consumer pushes data log entries to queues and everything is orchestrated by the manager, which also performs validation for MySQL and creates a status report if something doesn’t fit or connect.
This also drives great flexibility, enabling a new connector to be deployed in less than two weeks, as opposed to the three weeks that are typically required by other approaches.
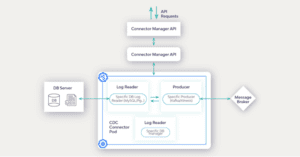
3. SSH connectivity and other topologies
We created an SSH tunnel as an external service that is embedded as a side car. This new solution aligns with multiple connecting topologies, as well as offers high performance and stability.
4. Centralized management
The Rivery solution can get messages at a very high capacity, bringing a lot of different data types very quickly from many sources, all with the ease and the clarity of centralized management.
5. A transactional process
The solution’s transactional process collects all the data that needs to be pushed, and also lets the user know where this collection started, to where exactly it would be pushed, and where it left off if stopped.
Having such visibility into the process is strategic to minimizing delays even when an event occurs and interrupts the process.
6. Flip/flop functionality
The solution leverages two queues instead of one, assuring that messages are accepted while at the same time more data can be fetched from the source without causing any processes to be blocked.
So, whenever one queue gets filled up, the data coming in goes into the second empty queue instead of creating a backlog. Only once the full queue is empty, can it be used again for new data coming in.
The benefit of this approach is not only about avoiding delays, at down to 10 seconds vs. 2-3 minutes with other approaches. The biggest benefit is that users can finally focus on the business logic instead of expending tons of energy on database replication.
In conclusion
With the Rivery ELT solution you get the six must-haves for overcoming some of CDC’s toughest challenges, effort-free, with:
- A very light programming language
- An architecture that drives efficiency and flexibility
- Support for SSH connectivity and other topologies
- Centralized management
- A transactional process
- Flip/flop functionality
And the benefit to you?
- Minimized delays
- Increased stability
- Scalability
- Enhanced efficiency
- More time to focus on business logic
Bottom line – no overhead, no headaches, just value.
But don’t just take my word for it. I invite you to see for yourself how the Rivery CDC platform can help you move data updates and changes in the fastest, most efficient, least overhead-intensive way. To see it in action, reach out to us here.



Minimize the firefighting. Maximize ROI on pipelines.

