





















CDC vs. Standard SQL Database Data Extraction

Operational databases are flooded. Storing endless data comes with a serious price tag that is often overlooked. After all, the storage of data is only useful if the data is put to use. Extracting all that data is costly and time-consuming. Without following best practices for extraction your bottom line will suffer. Organizations are beginning to realize the urgent need for efficient operational database data extraction.
SQL-based standard extraction and CDC (Change Data Capture) are the primary methods for this type of extraction. Choosing between the two depends on various factors, like data freshness requirements, volume, complexity, and specific use cases. In some cases, a combination of both will yield the most effective strategy.
To help guide you, the pros and cons of each method, let’s dive in.
What is operational database data extraction?
Operational databases are built to handle online transactional processing (OLTP) workloads, where numerous users execute small create, read, write and delete (crud) transactions against it. Data extraction from an operational database involves querying the data and moving the results set somewhere else, typically for the purpose of analyzing the extracted data and taking action using the found insights. A popular on-going data extraction process (also known as replication) would be from the operational database (i.e. MySQL, PostgreSQL, SQL Server, Oracle or MongoDB) to a cloud data lake or warehouse (i.e. AWS S3, Google Cloud Storage, Snowflake, Databricks or Google BigQuery).
When is operational database extraction needed?
Extracting data from an operational database serves many purposes, from powering analytical workflows with quality data, to simply creating data backups. Here are some common scenarios where it’s used:
Reporting and analysis: Data can be transformed and visualized for advanced analytics reporting and BI
Data warehousing construction: Incremental changes can be captured in real or near-time for up-to-date analytics on top of a consolidated source of truth
Data integration: Specific dataset pulls from source databases to sync with other operational systems
Improved data quality: Data errors are eradicated with data cleansing and validation, making room for downstream analysis and more accurate reporting
Regulatory compliance and auditing: To generate audit trails, track data lineage, and demonstrate compliance with data governance policies
System upgrades and data migration: Data can be transferred seamlessly from operational databases to new systems without disruption
Disaster recovery and backup: Replicating a complete database can help recover lost data and maintain data integrity during system failures
Testing and development: Complete real / representative datasets can be replicated to create thorough testing environments for software development, quality assurance, performance testing and software validation
Historical analysis and archiving: Retrospective analysis of past business performance and trends can be easily identified
Other instances where operational database extraction is required includes ongoing data lake ingestion, where the data is consistently updated and made analysis ready.
The two most common types of operational database extraction methods for these types of scenarios are standard-SQL and CDC. So which one is better?
Standard SQL-based database extraction vs. CDC
Choosing between Standard SQL-based data extraction and Change Data Capture (CDC – also known as Log based replication) isn’t always black and white—it really depends on the specific needs of your data project. Picture SQL-based data extraction like a tailored suit. It’s flexible, letting you create custom queries for data retrieval, join tables, and perform transformations. It’s super handy for dealing with complex logic.
Now, in contrast, think of CDC as your go-to news app. It instantly captures real-time data changes, be it modifications, insertions, or deletions, providing you with the freshest data at your fingertips. CDC is great for real-time analytics or data replication.
As a rule of thumb, CDC is generally the go-to for near real-time synchronization and efficient tracking of incremental changes. SQL-based extraction, meanwhile, can be your best friend if you’re after a more controlled extraction process. You can mix and match both in certain cases.
 Choosing between standard and log based (CDC) extraction when replicating data from MySQL
Choosing between standard and log based (CDC) extraction when replicating data from MySQL
When deciding between the two, please consider the following: how quickly you need the data, the volume of data, its complexity, and your specific use case. Let’s weigh in on each one in more detail.
CDC at a glance
If you are brand new to the term CDC, you may want to start here. CDC often acts as a personal data watchdog, keeping a keen eye on your data source, diligently noting any changes that occur. Instead of carrying out huge data transfers, CDC focuses on the changes, making data migrations feel like a breeze instead of a massive project.
CDC automatically tracks any alterations in your source dataset and swiftly transfers them to your target dataset. Kind of like a data courier service operating in real time.
This is super handy when you’re replicating data between databases. Unlike standard SQL batch processing, which only works during specific “batch windows” and uses up a chunk of your system resources, CDC is on the job round the clock. It keeps your target database updated instantly and uses stream processing to make near real-time modifications.
CDC use cases & benefits
CDC (Change Data Capture) is like a backstage pass to your database. Imagine you’re throwing a huge party (your database), and you want to make sure the right people (changed data) are getting in, and nobody’s sneaking past security (errors or deletions). That’s where CDC comes in.
Full database replication
Now, let’s say you want everyone at your party, not just a select few. Well, CDC can handle full replication of your entire database, no need to handpick tables, columns, or rows. It keeps an eye on everything, ensuring your replicated database is like a carbon copy of your original.
Real-time incremental changes
CDC captures and delivers all incremental changes in near- / real time, keeping the replica and source database synchronized without repeatedly extracting and processing the entire dataset. This is invaluable for backup, disaster recovery, or creating testing and analysis replicas.
Managing incremental changes without keys
Sometimes you might need to track metadata and sync changes without a proper designated key column such as “last update date” column (think of it like a guest list update time), well CDC can spot the newbies, the regulars and the party crashers (modified, inserted, or deleted records), keeping you in the loop even without that specific column. This helps to prevent data skewing and ensure data integrity.
Extracting deleted records
CDC captures makes it easy to track deleted rows at the sources and replicate those to the target to get a complete view of your data prior to analysis. This process is often referred to as deleted rows replication.
CDC doesn’t kill the party by adding an extra load on your operational database. It typically interacts with the database log, rather than access the tables directly. This helps to keep things running smoothly.
Quick CDC recap
CDC enables teams to replicate data instantly and incrementally. It automatically captures modifications from a source dataset, transferring them to the target dataset.
CDC excels in real-time data replications between databases, making it a wise choice for keeping your databases up to date. The beauty of CDC is that it lets teams analyze data without putting a strain on the production database.
See how to setup CDC replication in a few clicks: https://riveryio.wistia.com/medias/f2mjbyui2c
Standard-SQL extraction at a glance
Think of Standard SQL-based extraction as a super smart filter. It uses SQL queries to pick and choose the data that matters to you. You can set it to pull data based on certain events and intervals like the last time a column was updated, or even specific rows.
You don’t need to have it running 24/7. It’s all about cutting out the noise and focusing on the good stuff, saving you time and effort.
Standard-SQL use cases & benefits
Sometimes, you don’t need every single update from your database. Let’s say you have a COB (close of business day) process. Instead of constantly scanning for changes, you may only need to be notified about the final value captured on the day. SQL helps you set a reminder for intrinsic updates, and to work smarter.
Flexibility to filter and extract data in advance
Now, let’s talk about working smarter. Column-level selection and row filtering is like having an all-access pass but only visiting the spots that truly interest you. With SQL-based extraction, you can cherry-pick the columns you want and filter out the unnecessary rows. You can extract a specific date range or something that meets a certain criteria.
Complex business logic
Moving on to something a bit more complex. Sometimes, your data needs a little makeover before it leaves the source. Maybe it requires a quick join operation to create an “update key column,” or perhaps you need to replace IDs with something more user-friendly. SQL-based extraction is the answer.
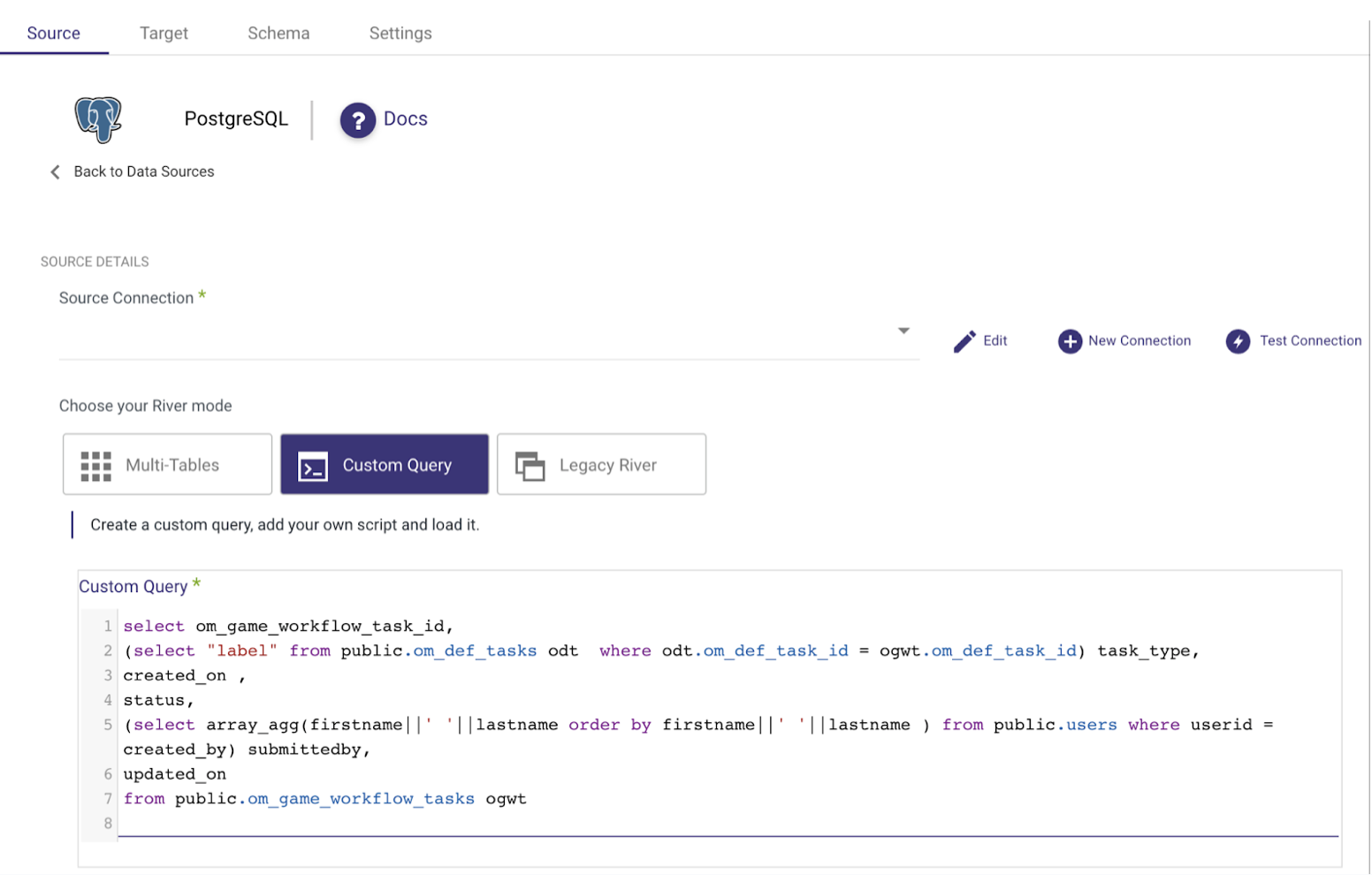
Sample custom query for standard extraction purposes
Granular control over extraction
Lastly, let’s discuss control. With SQL-based extraction, you get to call the shots. If your extraction process decides to act up and abruptly stops, no need to stress!
You can define how to pick up where it left off or handle any errors that arise. Having this level of control ensures your data extraction runs smoothly, providing the reliability you need to keep your business running like clockwork.
Quick Standard-SQL recap
The advantages of using a SQL-based extraction process are clear: it allows you to monitor specific changes, cherry pick relevant data, join complex tables, and gain full control over your data flow. All of this combined can help take your business operations to an entirely new level. With the efficient processing of SQL. In addition, sometimes CDC is just not an option for the source database you work with. In those cases, standard SQL is the only way to go.
CDC vs Standard-SQL
Use case | CDC | Standard SQL |
Reduce Database load | Preferred | Possible |
Near real time replication | Preferred | Possible |
Replicate (hard) deleted rows | V | NA |
Replication without keys | Preferred | Possible |
Point in time replication | Possible | Preferred |
Granular control over the replicated data points | Possible | Preferred |
To wrap up
When deciding between Change Data Capture (CDC) and Standard SQL-based data extraction, it all comes down to specific requirements and use cases. CDC wins in real-time synchronization, capturing precise incremental changes, and maintaining data integrity without burdening the database. The cost of data transfer is dramatically reduced, saving weeks and months of time.
SQL-based extraction, however, offers flexibility in pre-filtering and granular control over business logic. It enables customized queries, selective columns, row filtering, and custom error handling.
By recognizing the distinct benefits of each method and considering factors such as data volume, complexity, real-time requirements, and control needs, you can make the right decision.
Want to mix and match between the two? Rivery lets you do just that. Power up your data flow and fuel your business growth with compliant, flexible and reliable extraction processes.
Can't miss insights



Minimize the firefighting. Maximize ROI on pipelines.

