





















Howard Hughes saves $300K a year on data engineering with Rivery






The real estate community builder simplified their data stack with Rivery to generate tremendous efficiencies and cost savings.
We replaced a complex data integration stack that included Talend, dbt, Jenkins, and MySQL with a single platform that enabled us to reduce ETL time to less than 40 minutes, ingest three new sources (while still ingesting the original sources), and also implement historical snapshots, all with a data team of two.
Robert Dunlap, Data Architect, Howard Hughes
Results
- Automated forecasts: Howard Hughes Sales team can now automate forecast creations using a complete data view of their buyers’ activities.
- Access to new data sources: Howard Hughes Accounting team can now access two additional data sources and automate financial processes.
- $300K saved on data engineering: The data team is now fully in-house, eliminating prior dependencies on external data consultants for setup and maintenance.
- 83% savings on Data Warehouse cost: Moving the ETL process to use CDC with Rivery brought the cloud data warehouse cost to a ⅙ of the original cost
Howard Hughes develops at a massive and ambitious scale with having developed communities for more than 387,375 residents over 188,127 acres across six regions. To efficiently manage the development of these communities from planning to full execution the organization relies on a solid data foundation that allows tracking the financial status of this massive operation, running the sales processes, and the execution of unit management. Robert Dunlap, a seasoned expert, has been entrusted with the pivotal role of Data Architect to spearhead this critical data initiative.
Challenge
When Robert took on the responsibility of overseeing the data architecture, he was working with a mixture of legacy systems and processes alongside modern tooling:
- Talend was used for data ingestion and transformation
- dbt core was used for data transformation
- MySQL database was used to store different flags to trigger processes
- Jenkins was used to orchestrate and trigger dbt jobs
- Snowflake was used to store the data
The tools in place were set up in a convoluted way that was hard to make sense of with different tools and overlapping capabilities. It took time to learn how the system worked but more importantly, so many moving parts created a system that was bound to errors and hard to maintain.
We had four daily data loads to Snowflake that took three hours each. Every failure required a full restart of the process. We saw a lot of retry error message notifications but on the backend, it actually worked. Just checking if those errors were real or not took us a lot of time.
The legacy approach to data integration was costing the team time and money with multiple external consultants working to maintain the brittle data architecture. Due to the tools’ limitations, some data sources were not integrated, leaving the business users without integrated analytics for these sources.
Robert wanted to stop worrying about things breaking in the middle of the night and focus on optimizing the data architecture to achieve greater efficiency.
I just wanna build awesome, usable pipelines and dashboards that will make end users’ lives easier.
Solution
We took the initiative to see what wasn’t working and make significant improvements.
Robert started searching for a new approach. After some initial research, he came across Rivery and started a free trial. During the trial, Robert was able to quickly prove the foundation of his future data architecture building upon a single platform to handle the ingestion, transformation, orchestration and management of the data pipelines.
With Rivery’s no-code approach for database CDC data replication, API sources extract and load processes, push-down (in-database) SQL transformations, and overall streamlined UI, it was very easy to get started and deliver rapidly.
We replaced a complex data integration stack that included Talend, dbt, Jenkins, and MySQL with a single platform – Rivery.
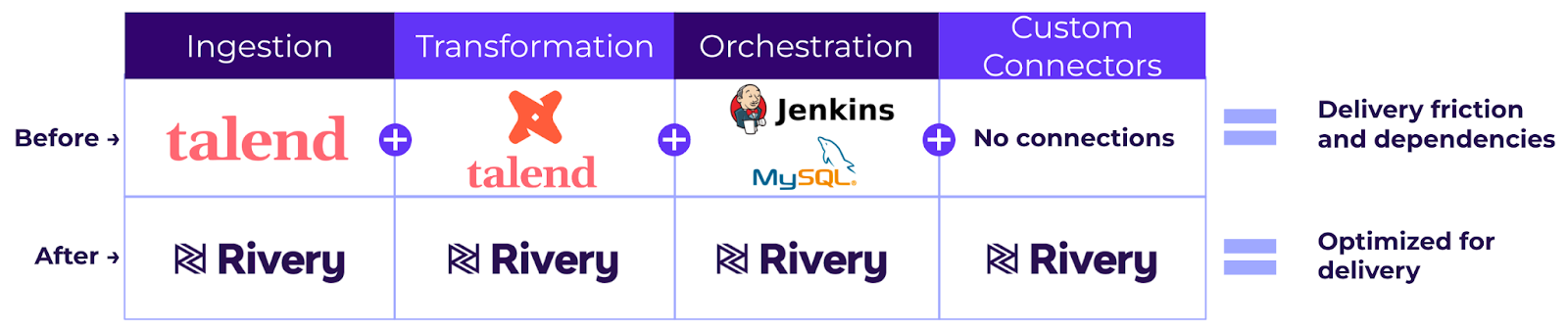
The migration process involved consolidating some processes and retaining the logic for others.
Since dbt and Rivery both use a SQL push-down-based approach for data transformation (in other words – running transformation in the database using an ELT process), migrating over from dbt involved copying the SQL queries into Rivery’s logic rivers and relying on Rivery’s native handling for incremental data loads.
For the data ingestion migration, the team was able to migrate the SQL Server data ingestion process to use the native Change Data Capture (CDC) data replication of Rivery in opposed to standard SQL batch queries to load the data into Snowflake.
While the migration was being worked on, Robert decided to experiment with Rivery’s data source custom connectivity to integrate with specific real estate software tools that were not integrated to date – Chatham and Blackline. Integrating those sources, allows the sales team to track their sales progression for new development projects.
For one of those sources, custom connectivity involved using Rivery’s managed Python to address unique requirements.
I didn’t know Python before trying Rivery and learned it with it. I’m a person that likes learning and diving into Python with Rivery made it easy.
Outcome
The streamlined approach to the data architecture foundation allowed to execute the migration internally and move to a data team of two instead of relying on six external consultants.
The new CDC-based ingestion process had a dramatic impact on the load time to Snowflake.
Rivery enabled us to reduce our ETL time to less than 40 minutes, ingest three new sources (while still ingesting the original sources), and also implement historical snapshots, all with a data team of two.
The move to CDC replication enabled not only a time reduction in the process but also great savings on the Snowflake consumption bill. With the new process taking less than 40 minutes compared to the previous three hours, the Snowflake compute engine usage was significantly smaller driving to ⅙ of the original bill.
Since the CDC process loads the data into Snowflake in the most efficient incremental fashion, the compute time required on the Snowflake end was dramatically reduced.
Our enhancements allowed us to cut our snowflake costs by 80%. (it’s) Crazy to look at the three-year chart and see the difference.
The new architecture allows the team to focus on the business asks and ensure all of the data is delivered consistently and effectively.
We are all about efficiency and so taking down and the costs and running things smoother is what we are driven by.
All in all, switching to Rivery reduced the overall data architecture costs by 60%-70% with most of our savings coming from Snowflake optimized usage and headcount.
Related case studies








