





















The Essential Guide to Enterprise DataOps
What is DataOps?
From data analysts, to marketers, to salespeople, every employee must now drive results with data. But today’s under-resourced data teams are overwhelmed by these growing expectations. To meet these new requirements, companies must implement an organization-wide framework to deliver high-quality data on-demand.
That’s why so many data teams are adopting DataOps.
DataOps speeds up the delivery of data and analytics to organizational stakeholders. The following will highlight everything data teams need to know about DataOps, from agile development, to DevOps, to DataOps toolchains, and much more.
Evolution from ETL to DataOps
For years, companies ingested data into on-premise relational databases using self-built data connectors. However, this process was too slow and expensive, and ETL tools gradually emerged for data ingestion. But issues with database scalability, data transformation, and continued deficiencies with data connectors limited the strength of the insights.
Years later, cloud data warehouses eliminated hardware scalability issues, and ETL platforms began to close the gap in terms of data connectors. Ingesting data was no longer the problem; transformation was. But soon, ELT platforms began to transform data inside the cloud data warehouse, leading to the rise in data lakes and unlimited insights from endlessly queryable data.
Era | Technology | Goal | Challenges |
Early 2000s | Relational | Supporting massive volumes of on-premise data | Scalability |
2005-2010 | Data | Turning data | Manual data source |
2010s | Cloud | Moving to the | Supporting a vast |
2020s | Orchestration - | Data touches | Data agility at scale, |
Today, the challenge facing data-driven companies is more about delivering data than generating it. Now, everyone in an organization needs data, and needs it in minutes, not in hours. However, most traditional ETL platforms are still reinforcing an outdated framework that silos data and puts it only in the hands of a “chosen few.” That’s why DataOps platforms are built for this new era.
DataOps platforms do not just generate, but also deliver, the right insights, at the right time, to the right stakeholder. With full data orchestration, DataOps platforms automate the democratization of data, from start to finish. DataOps platforms eliminate the rigid, top-down data culture facilitated by traditional ETL platforms, for a bottom-up system that provides stakeholders in the trenches with the data they need.
Agile Data Development
Iterative & Incremental Sprints Rapidly Produce the Right Data
In software engineering, agile is a development method based on adaptive planning, flexible modification, and continuous improvement. Agile breaks the development cycle down into smaller increments, called “sprints,” that last anywhere from one to four weeks. During sprints, cross-functional stakeholders collaborate throughout the process, spanning from planning, to coding, to testing. At the end of the sprint, the software product is demonstrated, and stakeholder feedback is incorporated.
DataOps applies agile development to data workflows, rather than to software products. Teams harness DataOps to build data workflows that automate data ingestion, transformation, and orchestration. Agile development is used to construct the data infrastructure that powers these workflows, such as data pipelines and SQL-based transformations. On a granular level, this data infrastructure is just source code, or infrastructure as code (IaC). Agile development treats IaC as a “software product.”
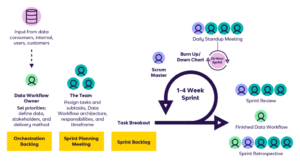
Within a DataOps framework, agile development relies on cross-functional teams to execute “data sprints” that deliver data and analytics to targeted stakeholders. Each team is composed of data managers (such as data engineers) and data consumers (such as salespeople). Feedback from stakeholders is incorporated continuously within the sprint process to quickly improve and update data assets.
Some of the top-level advantages for agile development in DataOps include:
- Faster delivery of data & analytics to stakeholders
- Shortened development time for data infrastructure
- More stakeholder input
- Rapid adaptation to changing priorities
- Constant updates & improvements to data assets
Agile development produces new data workflows, but DevOps is needed to operationalize them.
DataOps vs. DevOps
Combine Development and Operations to Push Data Workflows Live
Traditionally employed in software production, DevOps combines software development (Dev) with IT operations (Ops) to speed up time-to-launch for high-quality software. Closely related to agile development, DevOps merges the processes of building, testing, and deploying software into a single framework.
Although DataOps derives its name from DevOps, DataOps is not simply DevOps for data. The difference is that DevOps combines software development and IT operations to automate software deployments, while DataOps automates the ingestion, transformation, and orchestration of data workflows.
DataOps automatizes the quick deployment of data infrastructure built during the agile development phase. DevOps methods offer a number of advantages to DataOps teams, including:



Executed along with continuous integration, automated testing assesses factors such as security, API functionality, integrations, and other factors that speed up time-to-delivery.


DataOps Framework
DataOps team members develop data infrastructure in separate but nearly identical environments, and push changes live with point-and-click functionality after a predefined testing process.
DataOps, like DevOps, relies on automation to eliminate manual tasks and IT processes, for example:
- Data orchestration automates entire data workflows, from ingestion, to transformation, to delivery
- Auto-syncing developer source code with main branch
- Data infrastructure pushed live into production with one-click deployments
Until recently, teams could not apply the principles of DevOps to data infrastructure. This was due to the technical limitations of on-premise hardware. Unlike web and desktop software, data infrastructure relied on massive, unscalable on-premise data warehouses and servers. This greatly limited developer and test environments, continuous integration and delivery, and other key DevOps processes.

But with the advent of cloud data warehouses, hardware limitations disappeared. Now any team can simply clone the source code for data environments, including data infrastructure, an unlimited number of times within a cloud data warehouse. This unlocks a key facet of DevOps: running multiple environments at once. DataOps team members can develop data workflows in separate but nearly identical environments, and push changes live in a single click after a predefined testing process.
DataOps Team
What Does an Effective Team Look Like
DataOps is a flexible framework. By design, teams will include temporary stakeholders during the sprint process. However, a permanent group of data professionals must power every DataOps team. Each organization will form a different DataOps unit. But in the DataOps teams that we’ve worked with, certain skill sets are clearly in-demand.
Here are some of the personnel that often play key roles:
DataOps Position | DataOps Role |
Chief Data Officer | The CDO, or a similar executive, is accountable for the overall success of the DataOps initiative. The CDO is instrumental in driving the DataOps team to produce business-ready data that meets the needs of both data consumers and leadership. He/she will be responsible for the end-to-end business output and results of the initiative, and guarantee data security, quality, governance, and lifecycle of all data. |
Data | The data steward builds a data governance framework for all of the different stakeholders within an organization. He/she manages the ingestion, storage, processing, and transmission of data to internal and external systems. This forms the backbone of the DataOps framework. |
Data | The data quality analyst improves the quality and reliability of data for consumers. The person in this role is tasked with automating the detection of quality issues and addressing those issues during sprints. Higher data quality translates into better results and decision making for stakeholders. |
Data Engineer | The data engineer builds, deploys, and maintains the organization’s data infrastructure. This data infrastructure pushes data from source systems to the right stakeholder, in the right format, at the right time. A data engineer might also possess some data science skills, including modeling and AutoML. |
Data Scientist | The data scientist tells the story behind the data by producing advanced analytics and predictive insights for stakeholders. He/she converts big data into usable information, and charts optimal company operations. These enhanced insights enable stakeholders across the company to improve decision making and produce stronger results. |
Data/BI Analyst | The data/BI analyst manipulates, models, and visualizes data for data consumers. He/she discovers and interprets data so stakeholders can make strategic business decisions. |
Beyond technical skill sets, DataOps team members must possess critical personal qualities, such as leadership, communication, and the ability to work with employees outside of the data team. But there is still a last piece of the puzzle. DataOps teams must also have the right technology in place.
DataOps Toolchain
Combining Technologies to Power the DataOps Framework
Just as with DevOps, DataOps deployments have traditionally relied not on a single technology, but rather on toolchains of different solutions. A DataOps toolchain merges technology solutions with the other elements of the framework – agile, DevOps, and personnel – to drive business value for stakeholders.
An effective DataOps toolchain allows teams to focus on delivering insights, rather than on building and maintaining data infrastructure. Without the right toolchain, teams will spend a majority of their time updating data infrastructure, performing manual tasks, searching for siloed data, and other time-consuming processes.
These inefficiencies undermine the core advantages of DataOps, decreasing data delivery speed and data quality.
Although the specific technologies will vary, IBM has identified five steps for constructing a successful DataOps toolchain:
- Implement source control management: Using a source control system such as GitHub, teams can keep a source code record for all data infrastructure, ensuring repeatability, consistency, and recoverability.
- Automate DataOps processes & workflows: Automation is essential for DataOps, and this requires runtime flexibility for data workflows. To achieve this, a toolchain must incorporate data orchestration, data curation, data governance, metadata management, and self- service functionality.
- Embed data and logic tests: In order to validate the functionality of data workflows, toolchains must test inputs and outputs, and apply business logic to guarantee data quality and relevancy.
- Ensure consistent deployment: In keeping with the principles of DevOps, DataOps toolchains must enable teams to operate in separate testing and production environments. That way, the team can build and assess new data infrastructure without disrupting the live deployment.
- Push communications: A toolchain must automate notifications for key events, from alerting stakeholders to data availability, to flagging workflow failures for the data team.
DataOps Platform
Managing DataOps All “Under One Roof”
Companies often form DataOps toolchains by merging various technologies, from ETL tools, to Grafana, to Kafka. But the friction between these technologies, the lack of repeatability and agility, and the rising cost inefficiencies diminish the ROI of DataOps.
However, some new platforms combine the capabilities needed to build and maintain DataOps frameworks within a single solution, including:
- Ingest any data source: Ingest raw data from any data source, whether an API source or an on-premise database, CRM, ERP, or anything in between.
- Robust transformations: Use SQL, Python, or other business logic to transform data into the format stakeholders need.
- Full data orchestration: Facilitate DevOps by automating the entire data workflow, from ingestion, to transformation, to delivery.
- Infrastructure-as-code: Build and store data infrastructure, including data pipelines, as code. Manage them as software products during agile development.
- Version control: Keep records of your “software products” (i.e. data infrastructure) to ensure repeatability and redundancy
- Create separate environments: Generate separate data environments, from sandbox development workspaces, to testing, to live production. One click code updates – Push data workflows live into production with point-and-click, DevOps functionality.
- Automated data delivery: Automatically deliver data to stakeholders, internally, externally, or into a third-party app (i.e. Salesforce). Notify stakeholders of data availability through messaging apps (i.e. Slack) or email.
By combining capabilities such as these, DataOps platforms can significantly reduce the friction points within a DataOps toolchain. With the right DataOps platform, teams can maximize the methods, principles, and personnel of their framework, and deliver data to stakeholders with speed and agility.
DataOps: The New Paradigm for
Data Management
In today’s business environment, it’s a given that data drives the decision making and actions of every employee, from CEOs to SDRs. The next decade will usher in a renaissance of self-service analytics, with stakeholders across a company expecting bespoke, on-demand data in the blink of an eye.
But in many regards, the future is already here. After all, data consumers live in a world of one-click Amazon orders. How many times has a colleague approached you, two hours before a board meeting, asking for data that doesn’t even exist yet?
DataOps is designed for the rapid-fire data demands of today’s modern company. As the market becomes more competitive, and organizational data needs become more challenging, DataOps is a blueprint that enables data managers to meet, and exceed, the high expectations of data consumers and C-suite leadership alike.
