Python Hello World – Redshift
Last published
2022-03-16
Categories
Communication Collaboration
Type
Data Model
Integrates with



The Python Hello, World kit gives you all of the tools needed to start implementing python into your logic river flows through importing data into and out of a DataFrame, into and out of variables, and basic print statements and logging for debugging purposes. With the new python release, this Kit contains the best practices for python orchestration and implementation in the Rivery console.
Specifically, this kit shows the two available methods for moving data into a virtual python environment. Data is queried from your data warehouse to a custom dataframe, and data is taken from the results of a public api and moved to a variable. In the python code, we implement the best practice input procedures to move this metadata into a python virtual environment, modify it, and print it to the python console logs in preparation to load it back to a data warehouse.
This Kit includes…
- Data querying into a DataFrame
- An action river that loads data to a variable
- Logic that uses python to extract data from variables and DataFrames and prints it to the console logs
- Logic that takes a “DataFrame as a source” to move data from a DataFrame to the cloud data warehouse
Minimum RPU Consumption: 2.5 (2 RPU’s for logic and action river execution + 0.5 maximum for python logicode)
Configuring this Kit for use
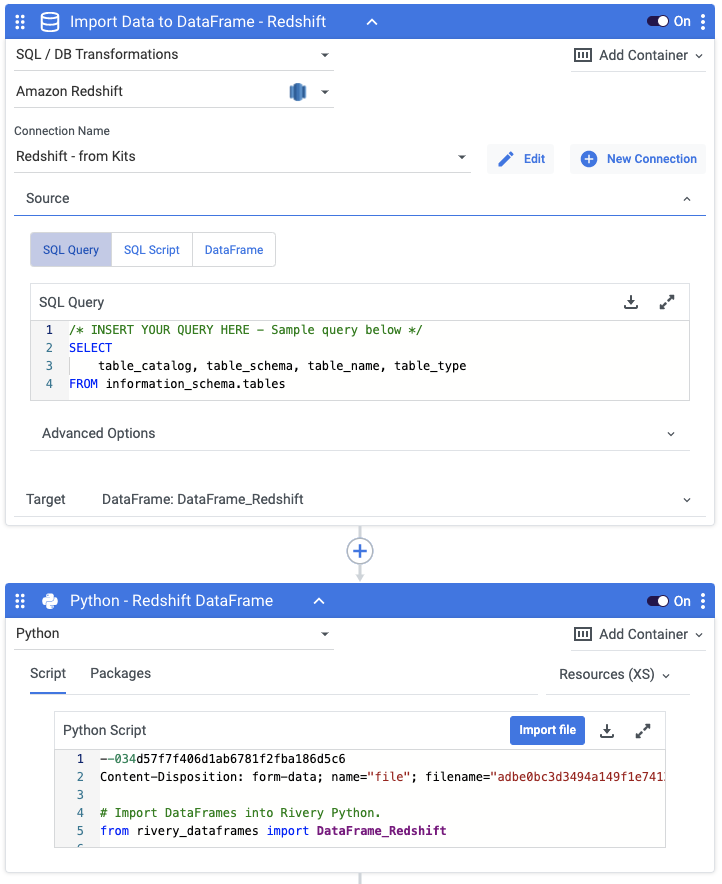
Queries
In order to extract information into DataFrames, you must write your query in the first container of the logic river flow. There is currently a sample query that will work for this example, but you can change it to any query you’d like.
Variables
In this Kit, there is one variables that are used to make for dynamic use of target configuration.
- {Schema_Redshift} is used in all Target configurations and queries as the target schema name if using Redshift
Go to the Variables menu on the left side navigation bar and create a variable for Schema_Redshift. Then fill in the value for the Redshift schema where you would like the data to land.
DataFrames
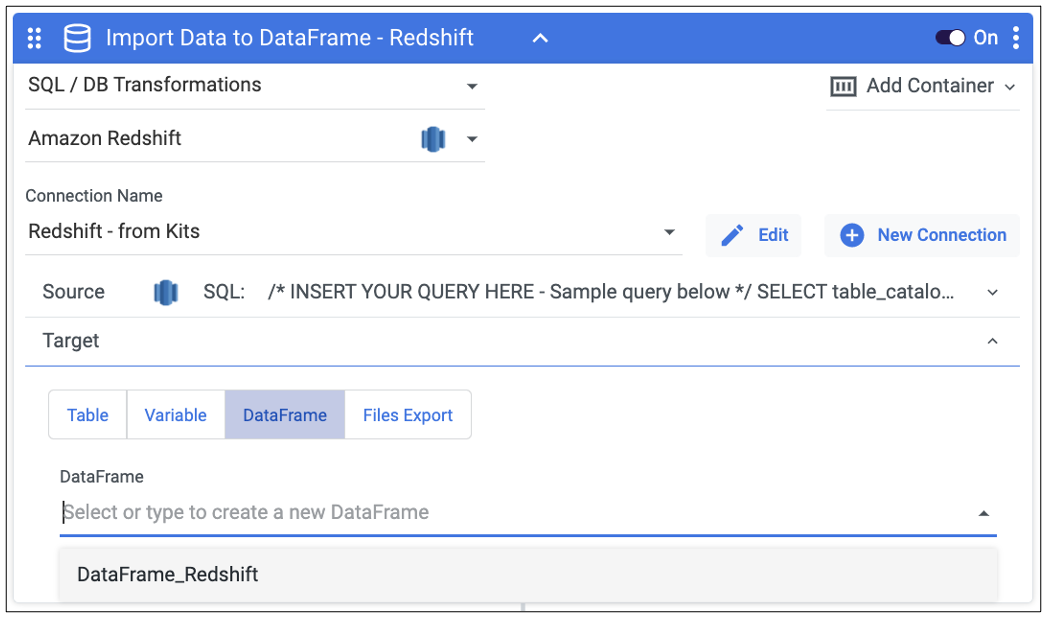
In this Kit, there is a DataFrame that needs to be created to hold the data from Redshift.
- {DataFrame_Redshift} is used to hold the results of your Redshift query (if applicable)
Go to the “DataFrames” menu on the right side navigation bar in a logic river and create a DataFrame for DataFrame_Redshift and select this DataFrame in all logic steps that reference DataFrames.
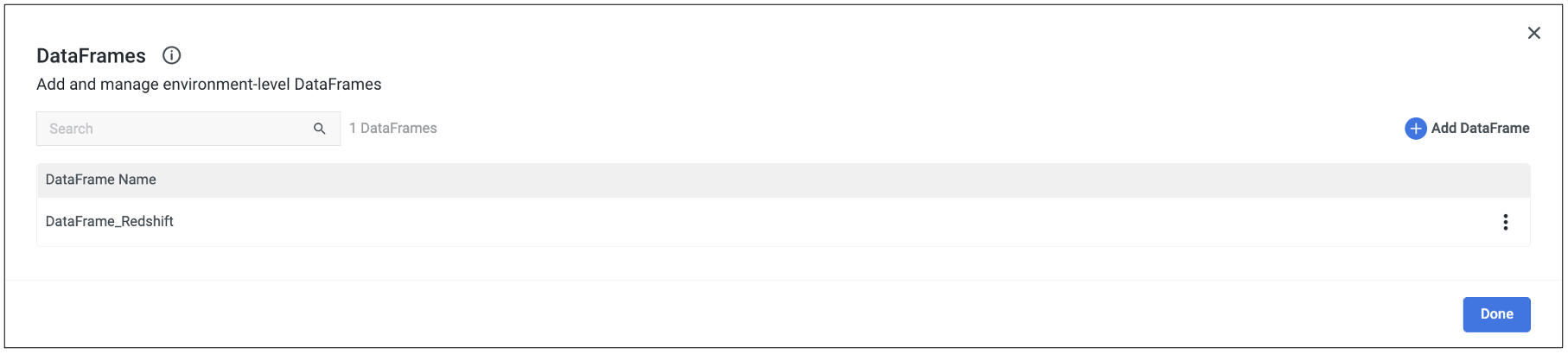
Once you’ve created the DataFrame within the logic river, use the DataFrame target drop down in the ‘Import Data to DataFrame – Redshift’ step to select the DataFrame in which you’d like the data to populated.
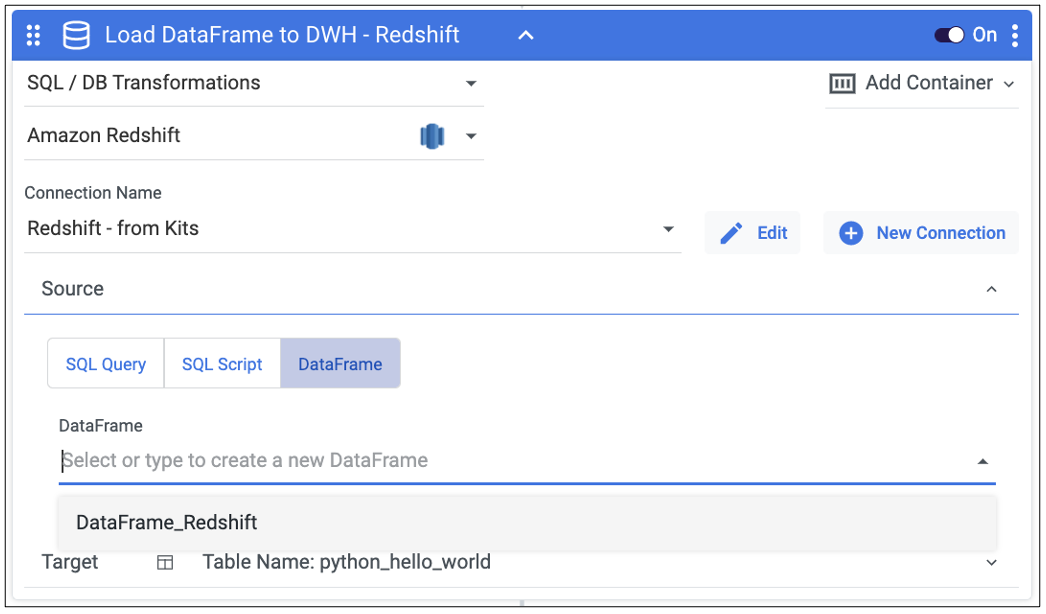
In the ‘Load DataFrame to DWH – Redshift’ step, select the DataFrame in the DataFrame source drop down from which you’d like the table to populated.
Connections
Kits are imported with ‘blank’ source and target connections. In order to use the kit, you have two options:
- Swap out blank connections with existing connections
- Add credentials to the blank connections that come with the imported Kit
Have questions about this Kit?
Set up a meeting with a Rivery solutions engineer.