Hubspot Object Updates – Databricks
Last published
2022-05-26
Categories
Sales Crm
Type
Data Activation
Integrates with


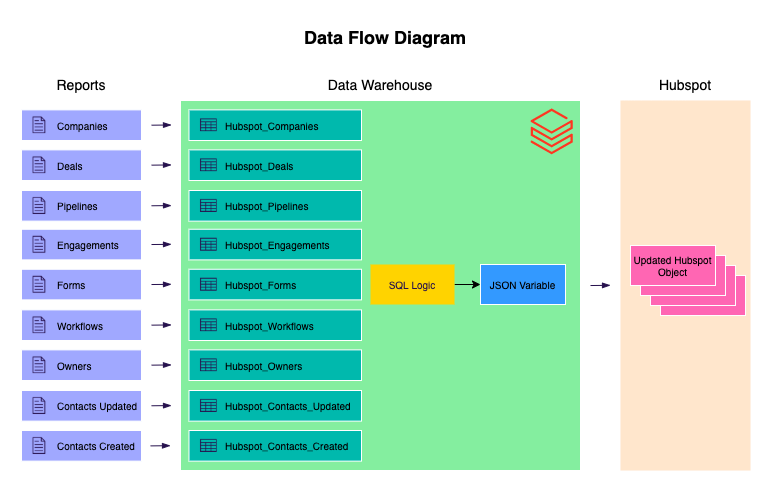
The Hubspot Object Updates Kit ingests entity data into the data warehouse and uses Hubspot’s API to update objects in Hubspot with additional information retrieved from the data warehouse. The flexible nature of the API gives the user the ability to update any of the CRM objects within Hubspot (Deals, Contacts, Companies, etc.) using this Kit.
This Kit includes…
- Hubspot entity data ingestion using the predefined reports functionality and an individual river for the Contacts report (not currently part of the predefined reports functionality)
- Sample SQL code to build a JSON structured variable which will update an object’s properties within Hubspot
- Action river that updates the internal Hubspot object
- Logic that orchestrates the Kit as a whole
For more information on the Hubspot API, see here.
Minimum RPU Consumption: 10
Configuring this Kit for use
Variables
In this Kit, there are two global variables that are used to make for dynamic use of target configuration.
- {Database_DB_Hubspot} is used in all Target configurations and queries as the target database name.
- {Hubspot_Alert_Group} is used as the alert email address(es) for when a river fails (optional).
Go to the Variables menu on the left side navigation bar and create variables for Database_DB_Hubspot and Hubspot_Alert_Group. Then fill in the values as the Databricks database where you would like the data to land and the email address(es) to which you would like the failure emails sent.
Beyond the global variables, there are two additional river variables that need to be initialized in order to get the Kit to complete successfully. Adding values to these already created parameters can be done within the “Hubspot Object Updates – Logic” river by clicking the top right “Variables” button.
- {hubspot_access_token} is the access token for the Hubspot developer application being used for this data push.
- {river_objects} is used as the object which the Kit will update within Hubspot. It can be any of the following values in the CRM object list: companies, contacts, deals, line_items, products, tickets, quotes. The sample code in the Kit is updating the Deals object in Hubspot.
Directions (Logic Updates)
The sample logic within the Kit can easily be changed to update different properties and/or Hubspot objects. In the code, the HUBSPOT_DEALS table from the “Hubspot Entities” river is joined to the SUPPLIER sample table within Databricks to update the “Phone” and “Account Balance” properties of the Deals objects.
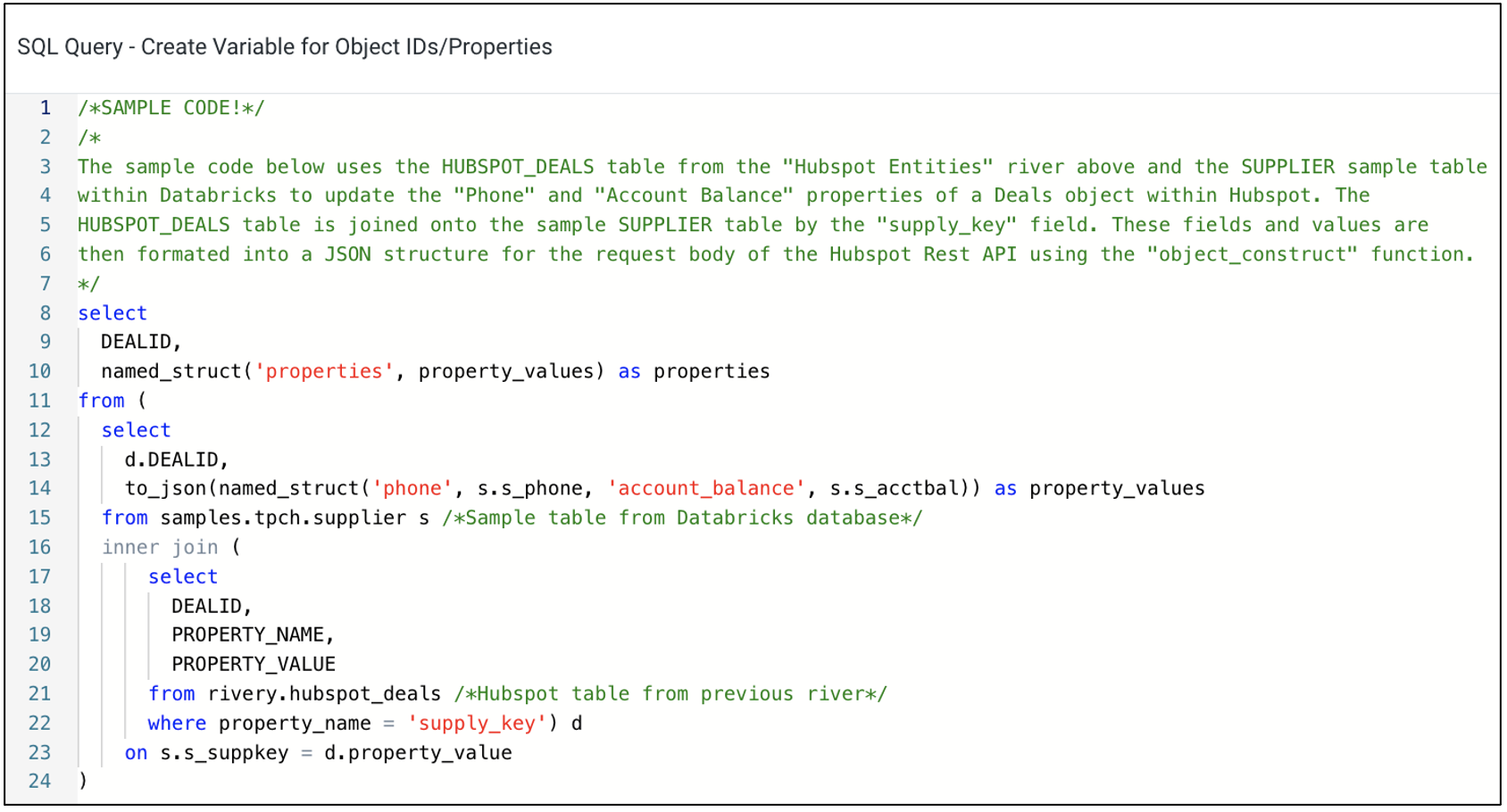
Updating this Kit to be personalized will require changing 4 parts of the sample logic.
- The entity table used will need to change depending on the type of object you’re updating.
- The sample logic joins the two tables on the SUPPLY_KEY field to get the values for key for the “Phone” and “Account Balance” properties. You’ll need to change this logic to join on a specific field within the Hubspot object and a table in the data warehouse.
- The DEALID field (line 9) will also need to be substituted based on the Hubspot object you’re looking to update.
- On line 14, the to_json(named_struct()) combination function builds the JSON structure for the API request body seen below. It requires an even number of arguments, the first being the property name within Hubspot and the second being the column that holds the value of the property.

Connections
If you ‘skip’ the connection section during import, Kits are imported with ‘blank’ source and target connections. In order to use the kit, you have two options:
- Swap out blank connections with existing connections
- Add credentials to the blank connections that come with the imported Kit