Slowly Changing Dimension – Snowflake
Last published
2022-02-01
Categories
Intelligence Analytics
Type
Data Model
Integrates with

The Slowly Changing Dimension (SCD) Kit provides logic to implement the type 4 SCD management methodology which tracks dimension changes for multiple tables by creating new historical tables.
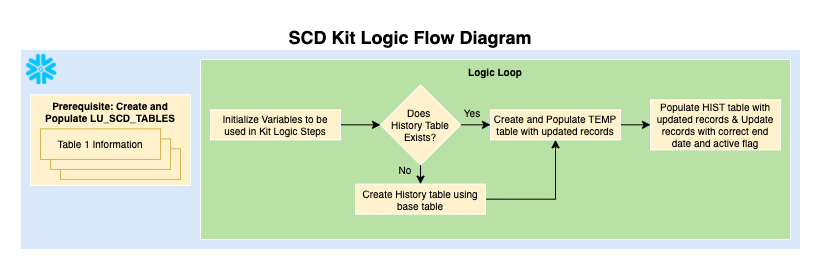
This Kit includes…
A logic river that creates and updates the historical table(s) based on the input from the look up table.
Minimum RPU Consumption: 1
Configuring this Kit for use
Variables
In this Kit, there are three variables that are used to make for dynamic use of target configuration.
- {Database_SCD} is used in all Target configurations and queries as the source and target database name.
- {Schema_SCD} is used in all Target configurations and queries as the source and target schema name.
- {SCD_Alert_Group} is used as the alert email address(es) for when a river fails (optional).
Go to the Variables menu on the left side navigation bar and create variables for Database_SCD, Schema_SCD, and SCD_Alert_Group. Fill in the values as the Snowflake database and schema where you would like the data to land and the email address(es) to which you would like the failure emails sent.
Prerequisites
Before running the Kit, you will need to specify the table(s) that you want to go through the SCD management methodology. In the first step of the logic river, there is a SQL script which holds code to create the LU_SCD_TABLES look-up table and an example insert statement to populate it. This logic only needs to be used once before being able to run the full river.
The look-up table holds all the information necessary to make this Kit work:
- SCD_TABLE_NAMES: The name of the original table that will go through the methodology to create a historical table
- MODIFIED_DATE_COLUMNS: The column name within the base table that identifies when the record has been last modified
- PRIMARY_KEYS_LISTS: The key(s) column(s) that, together, uniquely identifies each record in the table (if more than one column, this needs to be a comma-delimited list, eg: ‘channel,id’)
Once this table is populated and the base tables are all in the data warehouse, you can run the Kit to start creating these historical tables.
Example
The below example has been included to help you better understand the output results from this kit.
As described above, the first step in running this kit is to set up the look up table LU_SCD_TABLES. In the example, it is already created within the data warehouse, but this screen shot shows how to fill it out for the CUSTOMER_LIST table.

Once the look up table is populated and the selected table is added to the data warehouse, you will need to run the kit’s logic river. This creates and populates the new historical table, which in this example would be CUSTOMER_LIST_HIST. This next screen shot shows select statements from both the base table and the historical table. They are the same because this is the first instance of this table being added to the data warehouse.
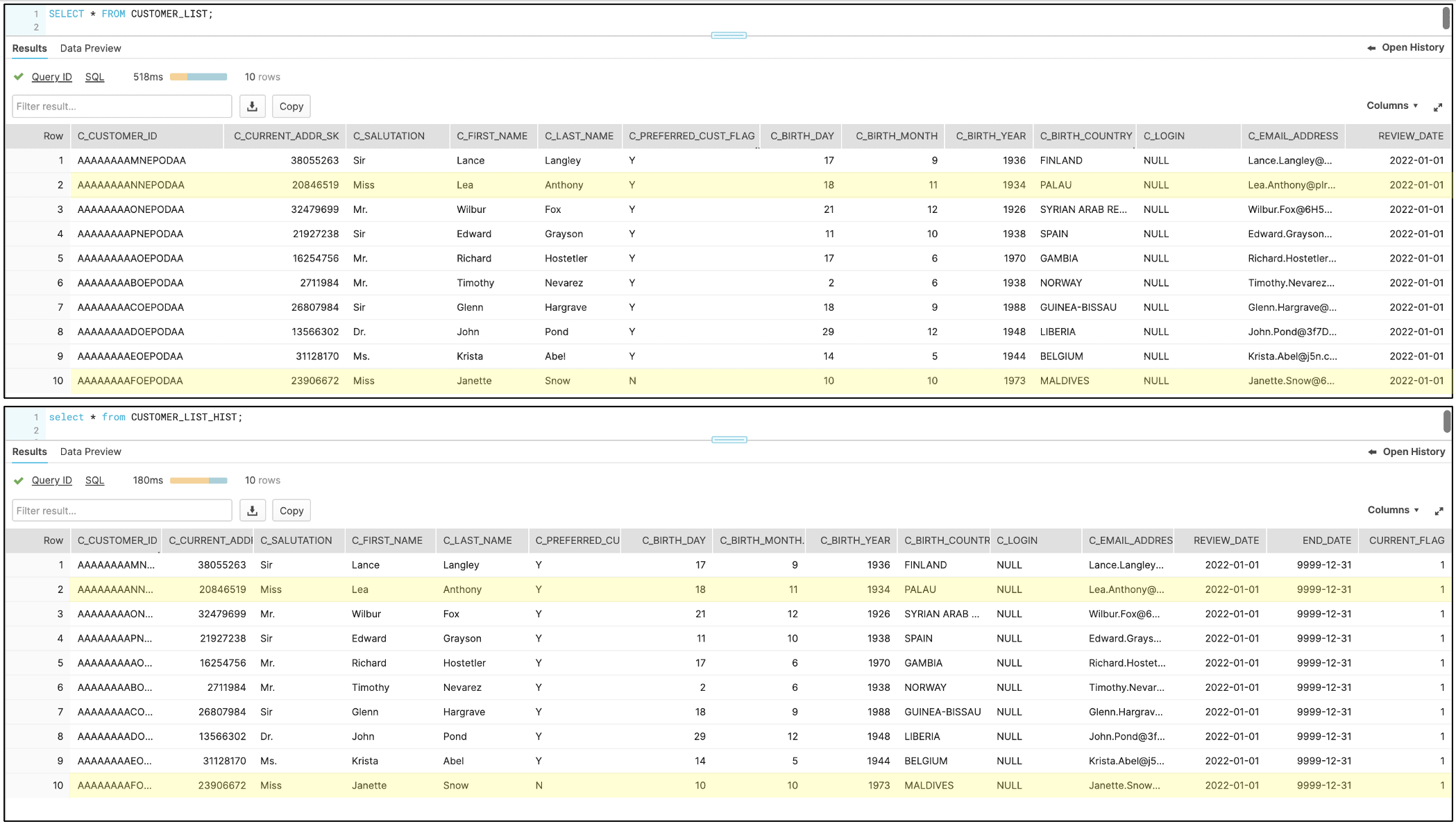
On January 31st, 2022 in this example, two of the cusomters in the list had their last names and salutations changed. This next screen shot shows the records in the base table that changed.
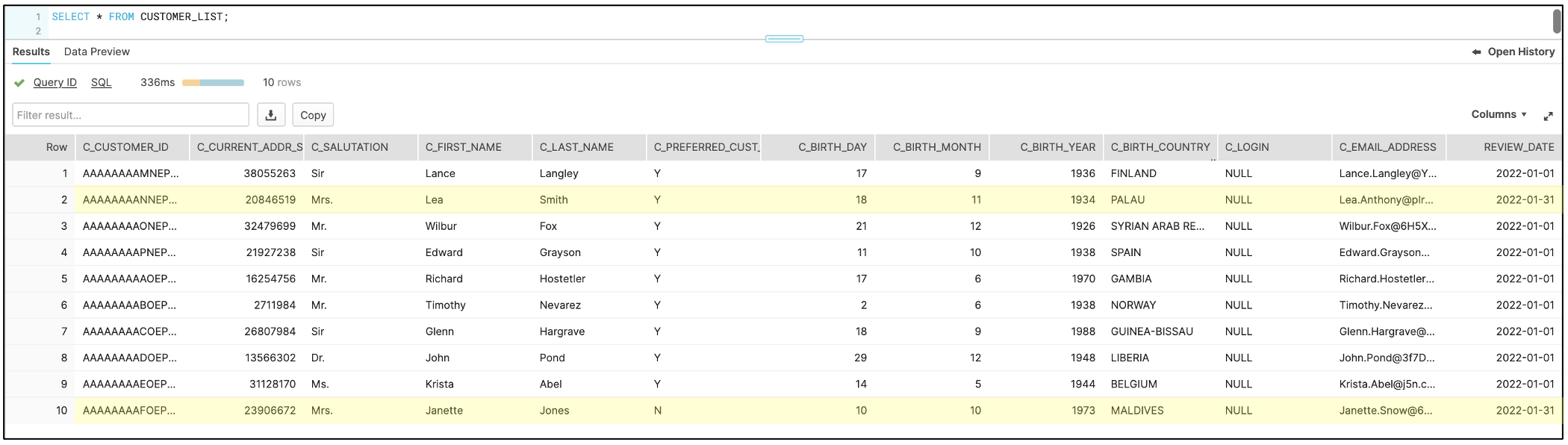
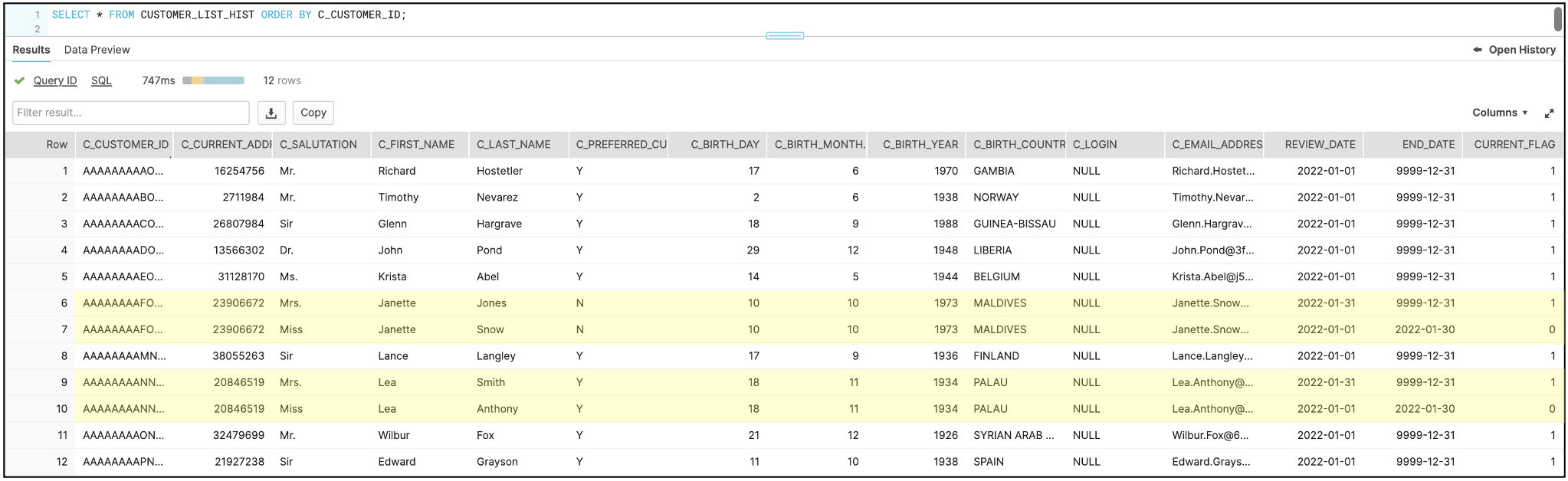
The next step in the process is to run the kit’s logic river again. This will add the newly updated records to the historical tables and change the END_DATE and CURRENT_FLAG values of the original records.
Connections
Kits are imported with ‘blank’ source and target connections. In order to use the kit, you have two options:
- Swap out blank connections with existing connections
- Add credentials to the blank connections that come with the imported Kit
Have questions about this Kit?
Set up a meeting with a Rivery solutions engineer.