Capterra to Databricks
Last published
2023-06-08
Categories
Marketing Advertising
Type
Community Connector
Integrates with


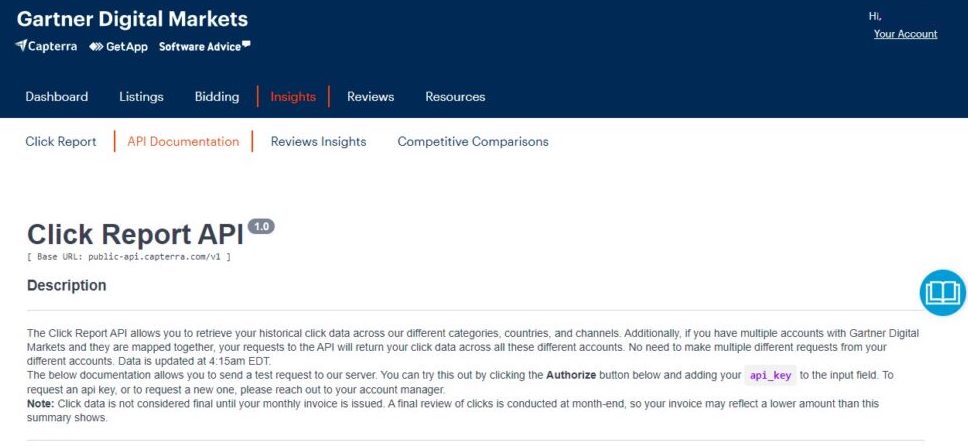
The Capterra kit uses the Gartner Click API to retrieve Capterra data, and load the data into your data lake.
This Kit includes…
Action river to connect to the Capterra Click API
Source to Target river to load the Capterra data into Databricks
Configuring this Kit for use
Before using this kit, you need to get your Capterra API Key. You'll need to reach out to the Capterra account manager, and you can find the instructions for the API KEY in the vendor portal under the insights tab.
Environment Variables
In this Kit, there are 3 environment variables that are used to make for dynamic use of target configuration.
{catalog_capterra} is used in all Target configurations and defaults to the hive_metastore if left empty.
{schema_capterra} is used in all Target configurations and queries as the target schema name.
{Capterra_Alert_Group} is used as the alert email address(es) for when a river fails (optional).
Go to the Variables menu on the left side navigation bar and create variables for catalog_capterra and schema_capterra. Fill in the values for the Databricks Catalog/Schema you'd like the data to land. The data will be landed in the table CAPTERRA_CLICKS.
Connections
Kits are imported with ‘blank’ source and target connections. In order to use the template, you have two options:
Swap out blank connections with existing connections
Add credentials to the blank connections that come with the imported template.
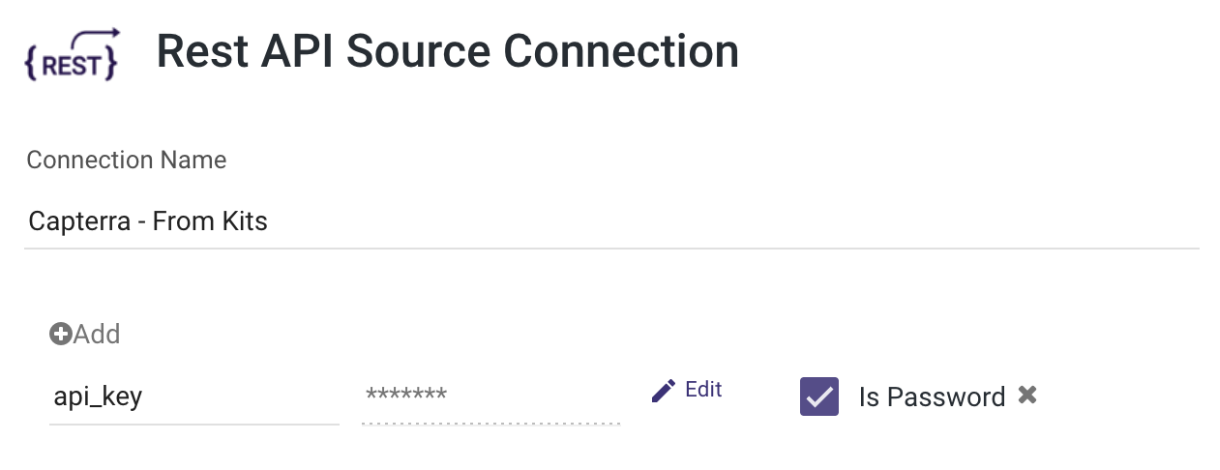
This kit requires a connection with the key "api_key" and its value
Have questions about this Kit or want more endpoints?
Send an email to helpme@rivery.io with the title “Help – Capterra to Databricks Kit”